Adding Tool Calling to Search Systems Without Breaking Retrieval, Reranking, or Control
TL;DR: Tool calling does not replace the search stack. In production, it adds a second control loop on top of query interpretation, retrieval, ranking, and reranking. The job is not to maximize tool use. The job is to place tool use where it improves coverage or actionability without degrading relevance, latency, reliability, safety, or rollback control.
Agentic search is still messy market language. AWS uses the term “agentic search”, OpenSearch OSS 3.2 still documents its version as experimental and not recommended for production, and Azure AI Search uses “agentic retrieval” while still labeling the current setup flow as public preview with no SLA and not recommended for production workloads (example). The naming varies, but the control problem does not: once tool use enters the stack, search gains a second control loop.
That second loop does not create a new search stack so much as a bounded capability layer on top of query interpretation, retrieval, ranking, reranking, and product constraints. Retrieval and reranking still decide what evidence is allowed to compete and what the product is willing to surface first.
The real production question is not whether a model can call a tool. It is where tool use belongs, what it may change, and how quickly the system can fall back when tool behavior degrades. If the second loop is not explicitly budgeted, observable, and constrained, relevance, latency discipline, and accountability start slipping before the demo does.
Current agentic retrieval APIs already expose reasoning and runtime budgets directly. Azure, for example, exposes retrievalReasoningEffort and maxRuntimeInSeconds. That is the right production instinct: agentic should describe a budgeted planning step, not an unbounded planning mood.
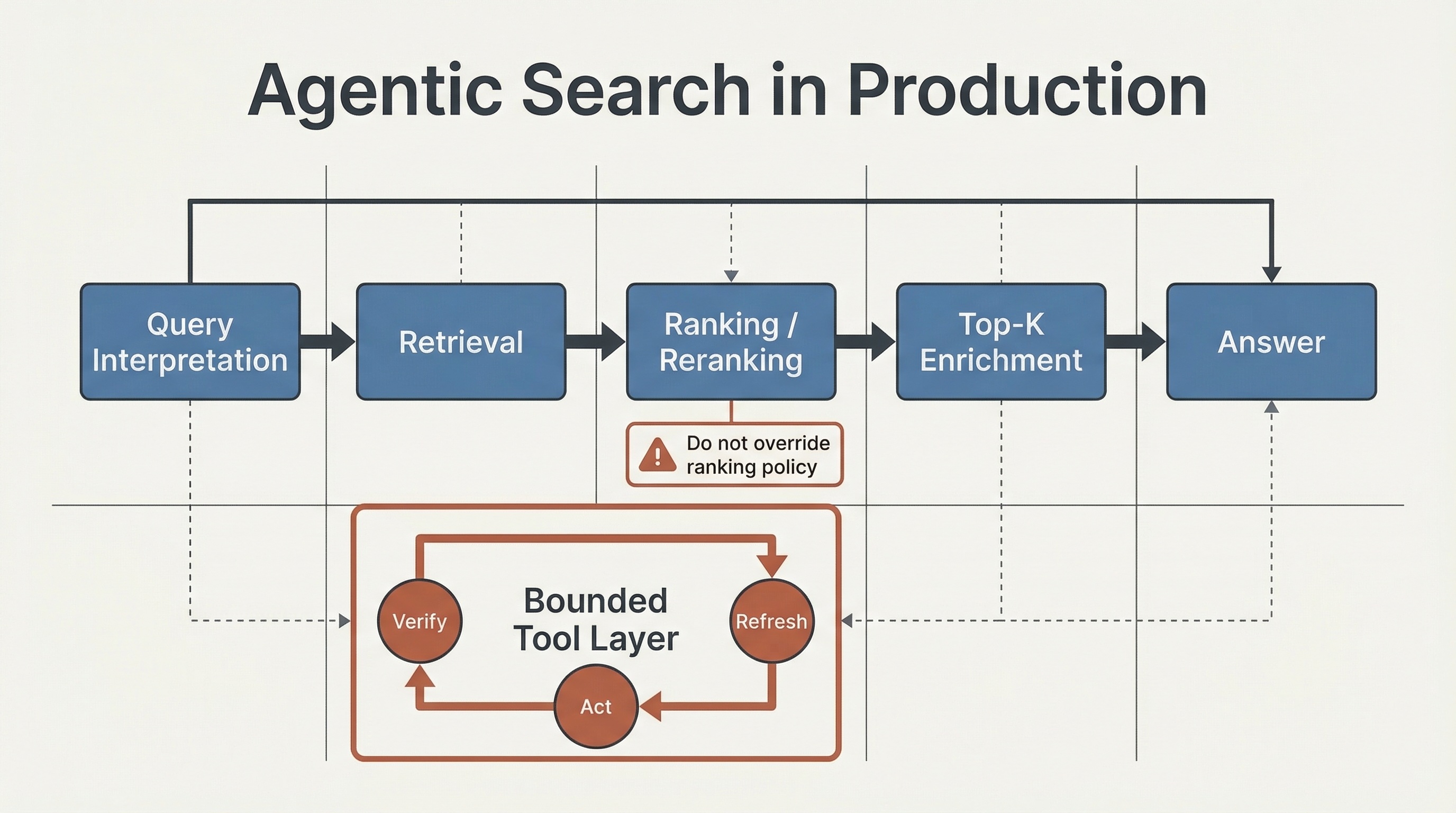
Primary search loop plus the second control loop introduced by tool calling.
What agentic search means in a production retrieval stack
The least glamorous definition is also the useful one:
Agentic search is a retrieval and reranking system with bounded tool use.
That wording keeps three scopes separate:
- Search system: query interpretation, retrieval, ranking, reranking, and product constraints.
- Capability layer: tools for enrichment, verification, permissions, freshness, or approved actions.
- Workflow layer: release gates, approvals, fallback paths, observability, and rollback discipline.
If those scopes blur together, the same user-visible regression can be misread as query rewriting, retrieval drift, reranking feature loss, tool latency, approval policy, or action failure.
Recent work such as SoK: Agentic RAG and Is Agentic RAG Worth It? points in the same direction: once retrieval and tool use become sequential decisions, evaluation gets harder and failure modes multiply quickly.
Retrieval and reranking remain the primary control loop
In production search, retrieval and reranking are control points, not just relevance stages.
Retrieval decides which evidence is even allowed to compete.
Reranking decides what the product is willing to show first under latency, business, and safety constraints.
In this article, I use ranking as the broader ordering policy across the stack and reranking as the higher-cost final refinement over the candidate set. The control problem gets sharpest at reranking time, which is why I keep that term explicit.
That is why the baseline architecture should still look like this:
user query
-> schema-bound query interpretation
-> retrieval
-> ranking / reranking
-> gated top-K enrichment
-> answer or next step
-> optional action gateNot this:
user query -> agent thinks -> agent calls tools -> agent decides what mattersThe first flow preserves a search contract. The second pushes critical ranking decisions into an open-ended loop. If tool output can silently outrank the reranker, relevance governance has already failed.
Retrieval and reranking remain the authority: the tool layer may interpret the query, enrich the top candidates, or execute an approved action, but it may not silently widen access scope, bypass ranking policy, or hide partial failure behind fluent output.
What the tool layer is not allowed to change
A production search system needs negative boundaries, not just positive use cases.
Tool use may:
- extract structured interpretation before retrieval;
- enrich top-K results after reranking;
- execute an approved action after answer selection.
Tool use should not:
- silently override reranking decisions;
- widen authorization scope;
- hide missing features or partial failures;
- convert untrusted retrieved text into privileged instructions;
- remove the ability to fall back to a tool-free baseline.
That is the contract. Tools extend the stack. They do not replace retrieval, reranking, policy, or fallback.
Treat tool outputs as typed features, not free-form authority
The safest way to integrate tool output into search is to decide what representation it enters the stack in.
Before retrieval, tool output should become typed query features: permissions, filters, normalized entities, or index choice.
After reranking, tool output should become late-bound result features or bounded evidence attached to specific candidates: availability, entitlement state, freshness, policy status, or confidence adjustments tied to known items.
Before action, tool output should become policy state or approval state, not autonomous execution.
It should not become a block of prose that the model treats as a new authority layer. Free-form tool text is hard to validate, compare across candidates, cache, or keep inside ranking policy. The structured tool guidance from OpenAI, Anthropic, and the latest MCP schema reference all point in the same direction: bounded structure scales better than tool narration.
If a tool result cannot be represented as a validated feature, a bounded evidence attachment, or an explicit approval state, it probably does not belong in the critical search path.
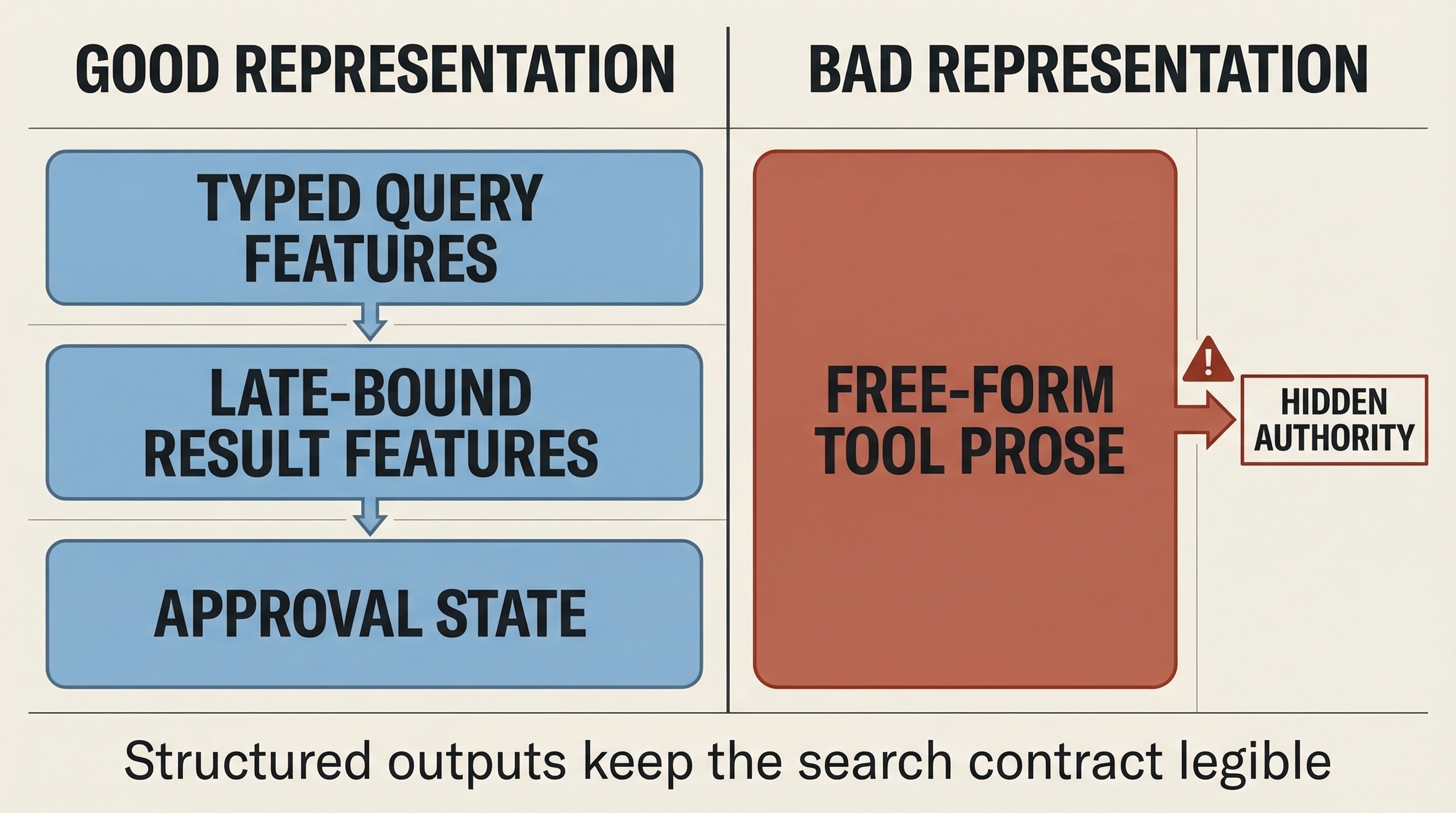
Tool outputs should enter search as typed features, bounded evidence, or approval state.
Before retrieval, after reranking, or after answer selection?
The safest way to add tools to a search system is to decide exactly where they belong in the loop.
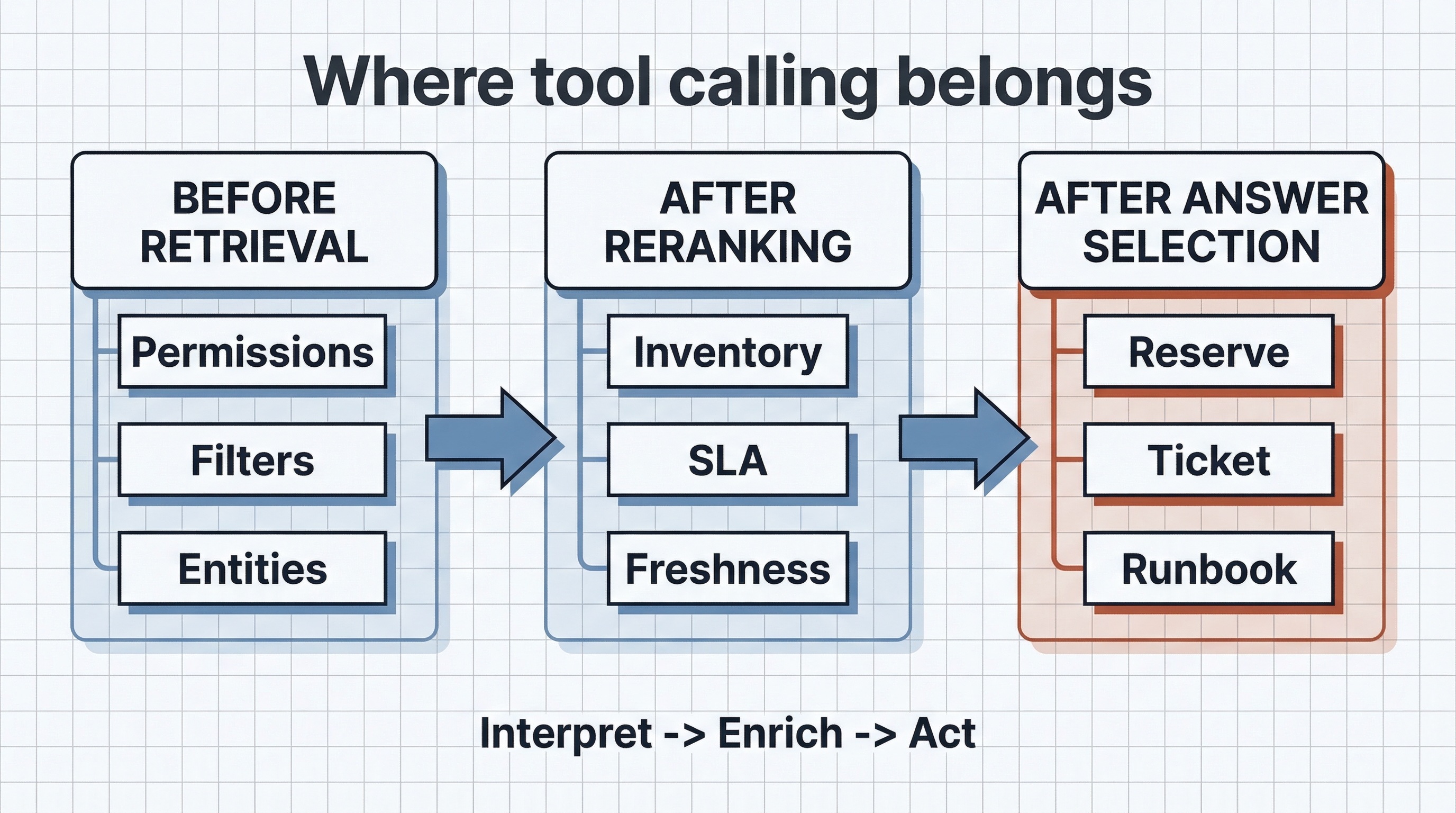
Three valid placements for tool calling in a production search stack.
Before retrieval
Use tools here only for narrow interpretation tasks:
- permissions lookup;
- index or vertical selection;
- schema-bound filter extraction;
- entity normalization.
This stage is for structure, not exploration. The output should stay machine-validated and bounded.
After reranking
This is the most search-native placement for tools:
- inventory checks;
- price or SLA refresh;
- entitlement verification;
- compliance or policy lookups;
- freshness checks for top-K results.
In this mode, retrieval and reranking decide what is worth spending tool budget on. Tools enrich the top of the result set instead of reshaping the whole search path.
After answer selection
This is where search turns into workflow:
- create ticket from the chosen result context;
- reserve item after user confirmation;
- open a merchant case;
- trigger a bounded runbook step.
That can be valuable, but it moves the system into a higher-risk operating class. Once the system can act, it needs approvals, least privilege, idempotency, and traceability. That is much closer to the release and policy discipline described in MLOps for a Support RAG Agent in 2026.
Use a hard placement rule:
- before retrieval for interpretation;
- after reranking for enrichment;
- after answer selection for approved action.
If the same request is calling tools in all three places by default, the system probably needs tighter budgets.
Fail-open versus fail-closed by tool role
The right failure policy depends on what the tool is allowed to change.
| Tool role | Default failure policy | What must never happen | User-visible behavior |
|---|---|---|---|
| Permissions or entitlement lookup before retrieval | Fail closed on widening scope; optionally fail open to a narrower safe subset | Never broaden access because a lookup failed | Fewer results is acceptable; unauthorized results are not |
| Query interpretation before retrieval | Fail open to the raw-query baseline | Never replace a healthy baseline with an unvalidated rewrite | Baseline results remain available |
| Top-K enrichment after reranking | Fail open to the reranked baseline with claim suppression | Never let missing tool features silently reshuffle the result set | Answer without the live claim; keep the baseline order |
| Post-answer action | Fail closed behind approval | Never execute side effects on timeout, ambiguity, or denied approval | Keep the answer path; disable the action path |
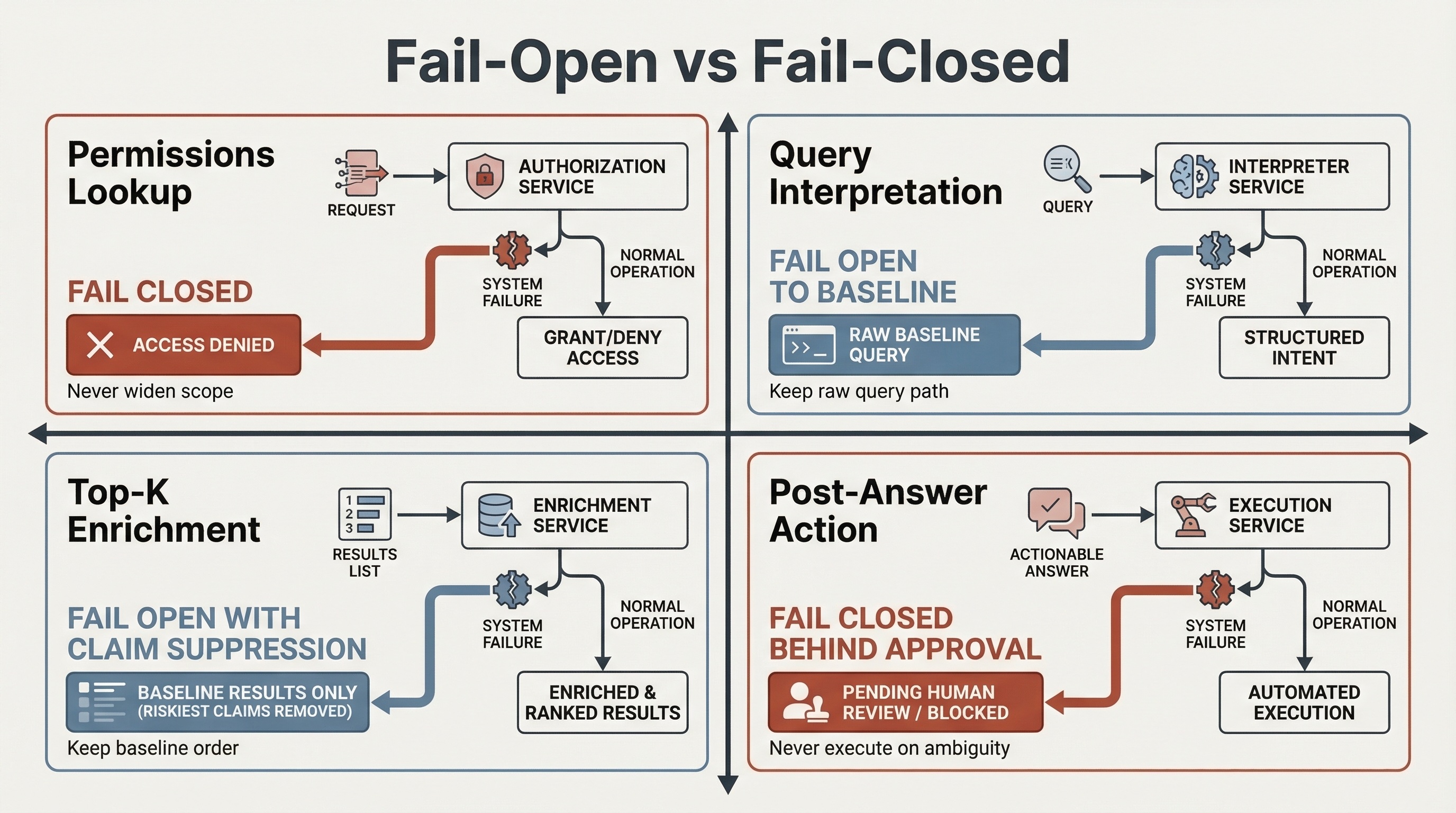
Failure policy depends on what the tool is allowed to change.
Four production patterns for retrieval, reranking, and tool orchestration
| Pattern | When to use | Main benefit | Main risk | Latency impact | Control requirement | Fallback strategy |
|---|---|---|---|---|---|---|
| Structured pre-retrieval interpretation | Noisy queries, permissions-aware search, filter extraction, multi-index routing | Better query structure without changing the search contract | Query rewriting can drift from original intent | Low to medium | Strict schemas, bounded outputs, log original and interpreted query | Revert to raw query plus baseline retrieval |
| Retrieval-first with gated tool escalation | Most queries succeed with baseline search, but some need freshness or verification | Preserves the main retrieval path and spends tool budget only on ambiguous cases | Tool escalation becomes the happy path over time | Low for most traffic, medium on escalated queries | Explicit escalation rules, per-request tool budgets, clear fallback thresholds | Answer from baseline results with reduced confidence or narrower claims |
| Post-ranking top-K enrichment | Search quality depends on dynamic features such as inventory, entitlement, or policy | Fresh signals improve precision where they matter most | Partial tool failures distort reranking | Medium | Per-tool timeouts, default feature handling, rerank robustness checks | Keep reranked baseline and mark enrichment unavailable |
| Post-answer action with approval | Users need the system to act after selecting a result | Higher task completion without leaving the search flow | Side effects, access abuse, duplicate actions | Medium to high | Approval gates, least privilege, idempotency keys, audit logs | Keep the answer path, disable the action path, and hand off to a deterministic workflow |
The most common failure is to skip directly from interpretation to action. That is how teams end up with action-rich demos and weak search reliability.
If you want a platform-backed example of retrieval-first agentic design, this Microsoft Build session is the closest companion to the architecture described here.
Microsoft Build session on retrieval-first agentic design with Azure AI Search.
Production controls for tool use
Tool calling should be controlled with the same discipline applied to any other production interface.
1. Strict schemas and bounded outputs
OpenAI’s function calling guide, Anthropic’s guidance on writing tools for agents, and the current MCP tools and schema reference all push toward the same operating rule: if a tool can accept arbitrary shape and return arbitrary text, it is not production-ready. In OpenAI terms, this is where strict schema handling matters.
In search, output shape matters as much as input shape. The reranker, fallback logic, and observability pipeline need to know whether a tool returns late-bound features, structured evidence, or action state. An input-only contract is not enough.
A stronger contract looks like this. inputSchema, outputSchema, and annotations follow the current MCP surface; slo, execution, and ownership are the runtime policy that the search stack should add around it:
{
"name": "inventory_lookup",
"title": "Inventory Lookup",
"description": "Return live availability for a bounded set of catalog items.",
"inputSchema": {
"type": "object",
"required": ["skuIds", "region"],
"properties": {
"skuIds": {
"type": "array",
"items": { "type": "string" },
"maxItems": 20
},
"region": { "type": "string" },
"timeoutMs": { "type": ["integer", "null"] }
},
"additionalProperties": false
},
"outputSchema": {
"type": "object",
"required": ["items"],
"properties": {
"items": {
"type": "array",
"items": {
"type": "object",
"required": ["skuId", "availability", "updatedAt"],
"properties": {
"skuId": { "type": "string" },
"availability": {
"type": "string",
"enum": ["in_stock", "low_stock", "out_of_stock"]
},
"updatedAt": { "type": "string" }
},
"additionalProperties": false
}
}
},
"additionalProperties": false
},
"annotations": {
"readOnlyHint": true,
"destructiveHint": false,
"idempotentHint": true,
"openWorldHint": false
},
"execution": {
"taskSupport": "forbidden"
},
"slo": {
"p95Ms": 250,
"failPolicy": "open_to_reranked_baseline"
},
"ownership": {
"team": "catalog-platform",
"approvalRequired": false
}
}Two details matter here. First, outputSchema reduces contract drift between tool owners and search owners. Second, mutability, idempotency, and open-world hints help decide whether a tool belongs on the answer path, the action path, or nowhere near the critical path.
Hints still do not replace trust. If the server is untrusted, the client should not blindly trust its self-description. The rule is blunt: strict schemas are not polish. They are the difference between tool calling and stringly typed automation.
2. Tool allowlisting and call discipline
The model should not discover its authority at runtime.
Use real control primitives:
tool_choicewhen the workflow should force, forbid, or narrow tool behavior;allowed_toolsor equivalent allowlisting when only a subset should be callable in a given stage;- no parallel tool calls where determinism matters more than raw throughput, for example
parallel_tool_calls=false; - per-stage tool catalogs instead of one giant global tool list.
This is also where cache and token discipline matter. Tool definitions and tool outputs both compete with retrieval context. Large catalogs and oversized outputs are an easy way to pay more for lower clarity.
In current function-calling APIs, allowed_tools is also a cost-control primitive. It lets the runtime narrow callable tools without constantly replacing the full tool list, which helps preserve prompt-caching savings.
3. Approval gates and MCP trust boundaries
If the stack uses MCP, pin the protocol version and treat transport and trust as first-class design constraints. As of March 21, 2026, the current MCP spec revision is 2025-11-25, with relevant details in the tools, authorization, and transports sections.
For practical design, that means:
- treat remote tool boundaries as trust boundaries;
- require approval for high-impact actions;
- keep read and write scopes separate;
- prefer trusted connectors over arbitrary third-party proxies;
- keep a per-tool owner and review path.
OWASP’s current MCP-specific guidance is worth folding into the same review path: the third-party MCP servers cheat sheet and A Practical Guide for Secure MCP Server Development both emphasize authentication, authorization, sandboxing, secure discovery, session isolation, and auditability. Those are not separate concerns from search quality. They define how much authority the tool layer can safely hold.
3.5 Authorization, consent, and token boundaries are part of ranking control
Authorization bugs do not sit beside search quality. They distort it.
If a tool can widen access scope, forward the wrong token, or bypass an approval boundary, the failure is not only security-related. It changes which documents, entities, or actions are even eligible to appear in the user-visible path.
For MCP-based integrations, that means four explicit rules:
- approvals stay on by default for remote MCP tools;
- the MCP server validates that tokens were issued specifically for that server;
- tokens are never passed through to upstream APIs;
- read scopes, write scopes, and approval flows stay separate.
OpenAI’s MCP and connectors guide and agent safety guidance push toward the same operating model, while the MCP authorization spec makes token audience binding explicit. This is why consent belongs in the same design review as ranking policy. If the system can silently cross a trust boundary, it can silently change the result contract too.
4. Trace grading and runtime metrics
In production, prompt quality matters less than control quality.
You need a trace that covers:
- original query;
- interpreted query;
- retrieval candidates;
- reranking decision surface;
- tool-call count;
- tool latency and error rate;
- fallback path chosen;
- final answer or action;
- business outcome.
This is where OpenAI’s trace grading and Agents SDK tracing stop being optional. On the telemetry side, the OpenTelemetry GenAI semantic conventions are worth adopting, with one caveat: the current GenAI semantic conventions are still marked Development, so version pinning and compatibility review are part of the work.
Without this layer, every failure looks the same: results got worse.
4.5 Telemetry contract for the second control loop
A trace is only useful if it lets the team answer the regression question quickly.
For every bad session, the on-call engineer should be able to tell:
- Did interpretation change the query?
- Did retrieval quality drop?
- Did reranking lose feature coverage?
- Did a tool timeout, error, or get denied?
- Did the system fall back cleanly?
At minimum, log:
- original query and interpreted query;
- retrieval candidate count and retrieval quality slice;
- reranker feature coverage;
gen_ai.client.operation.duration;gen_ai.client.token.usage;mcp.client.operation.duration;mcp.server.operation.duration;mcp.method.name;mcp.session.id;mcp.protocol.version;error.type;- final fallback path and business outcome.
The OpenTelemetry GenAI metrics and MCP semantic conventions already split these signals out, but both sets are still evolving and current semantic convention elements remain in Development. Pin the emitted semantic-convention version and migrate deliberately.
If those fields are missing, incident review turns into guesswork and ranking regressions get misclassified as model regressions.
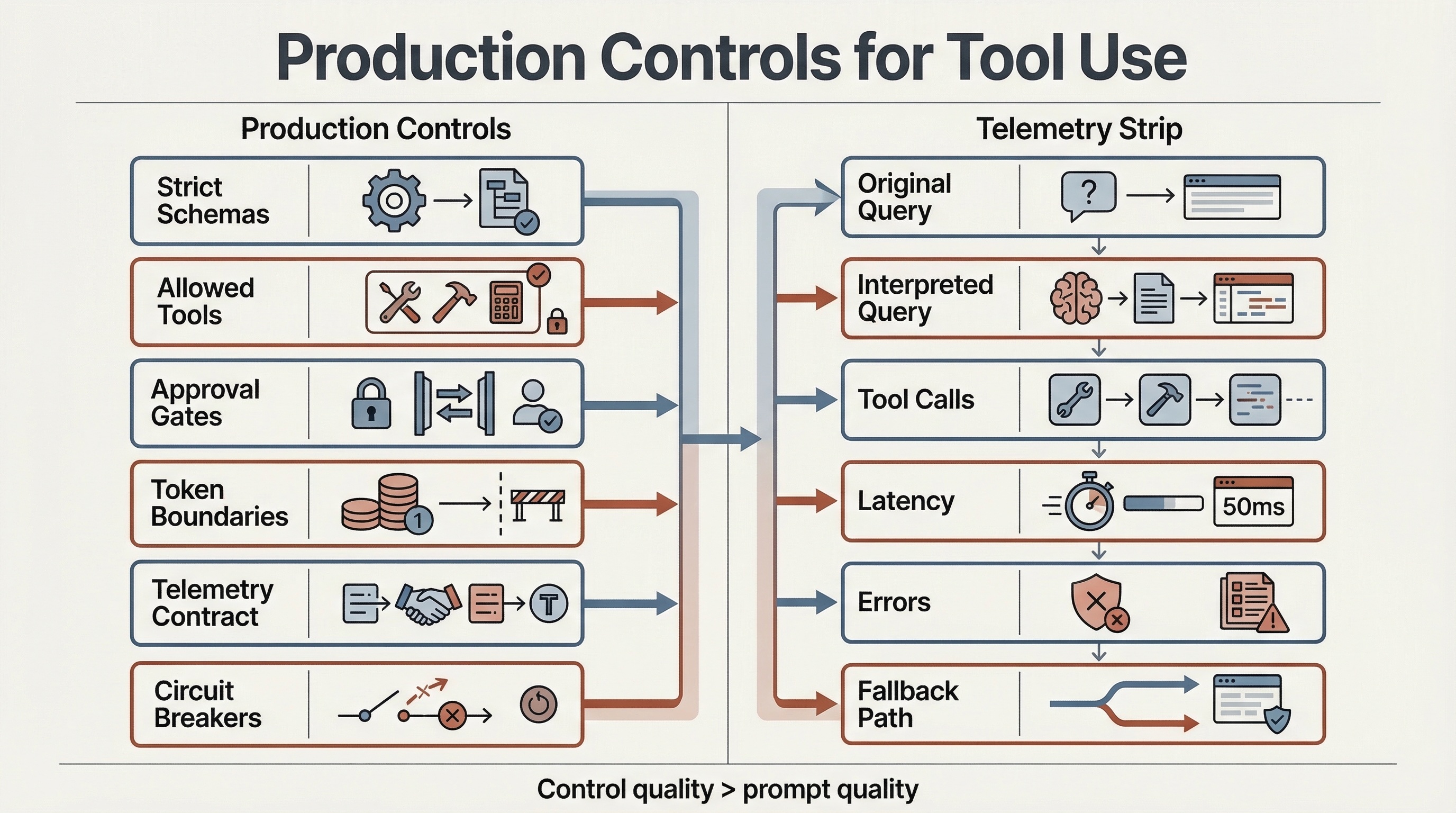
Control surfaces and telemetry fields that keep the second control loop governable.
5. Kill switches, circuit breakers, and degraded mode
The clean search path should survive tool failure.
This is where the fail-open versus fail-closed policy becomes real operating behavior rather than prose.
At minimum, the runtime needs:
- a global no-tool switch for emergency rollback;
- per-tool feature flags so one bad dependency does not disable the whole query path;
- circuit breakers for repeated tool timeouts or malformed responses;
- cancellation propagation so abandoned requests do not keep running downstream;
- explicit fail-open versus fail-closed decisions per tool role;
- fallback-on-timeout behavior that preserves the reranked baseline.
If the system cannot force a tool-free path, short-circuit a degraded dependency, and preserve the baseline answer under timeout, the operating model is still incomplete.
Search-specific evals and release gates
Search systems break first in the metrics. The problem is that agentic systems now add a second set of metrics that can hide inside the first.
| Metric group | Example metrics | What it tells you | Release gate example |
|---|---|---|---|
| Retrieval | Recall@K, nDCG@K, rewritten-vs-original query delta | Whether interpretation or tool-assisted rewriting changed evidence quality | Block if retrieval quality drops beyond the agreed tolerance |
| Reranking | Win rate, relevance delta, feature coverage | Whether the reranker still improves the candidate set under tool enrichment | Block if reranker win rate falls or feature coverage becomes unstable |
| Tools | Tool-call rate, redundant tool-call rate, invalid-parameter rate, timeout rate | Whether tool placement is bounded and reliable | Block if call rate or timeout rate exceeds budget |
| Latency | p95, p99, tool overhead delta, cancellation rate | Whether the second control loop is breaking the main SLO | Block if tool overhead breaches latency budget |
| Control | Fallback rate, approval rate, unsafe action attempts | Whether the system stays governable under real traffic | Block if fallback spikes or unsafe attempts rise |
| Economics | Cost per successful session, tool cost share, token growth | Whether added capability is worth the operational cost | Block if session economics worsen without offsetting quality gains |
Three practical release rules follow from that table:
- Log both the original and interpreted query. If you do not, retrieval drift becomes hard to attribute.
- Track feature coverage in post-ranking enrichment. Missing tool features can quietly bias the reranker.
- Gate on session-level value, not request-level cleverness. A more agentic path is only better if it improves outcomes without breaking the budget.
Worked example: e-commerce search with top-K enrichment
Take a query like:
need a carry-on roller bag under $200 that fits Ryanair and can arrive by friday
The production path should look like this:
query
-> structured interpretation
-> retrieval
-> reranking
-> top-K enrichment
-> answer
-> optional reserve-item action behind approvalStep 1. Structured interpretation
The model does not search yet. It extracts typed query features:
- product type: carry-on roller bag
- price ceiling: 200 USD
- airline constraint: Ryanair cabin fit
- delivery window: by Friday
This stage should return a validated feature object, not a free-form query essay.
Step 2. Retrieval and reranking
The retriever pulls candidates from the catalog. The reranker then orders them using the normal product contract:
- textual relevance;
- attribute fit;
- marketplace or catalog constraints;
- personalization where allowed;
- business rules already encoded in the stack.
At this stage, the result set should already be good enough to answer in degraded mode.
Step 3. Top-K enrichment
Only the top items get fresh tool calls:
- live inventory;
- current delivery promise;
- cabin-fit policy lookup;
- merchant restrictions if needed.
This is where the tool budget is spent. Not on the whole catalog. The result should come back as late-bound result features or bounded evidence tied to specific candidates, not as a prose block that can quietly override the reranked order.
Step 4. Answer path
The system answers with the best few options and grounds the answer in structured product attributes plus late-bound live features where available.
Step 5. Action path
If the user wants to reserve one of the results for pickup or add it to a protected cart flow, that is a separate step. It should cross an approval or explicit confirmation boundary, not happen as a side effect of the answer. The action path should carry approval state and idempotency context, not autonomous execution.
Fallback behavior
If the cabin-fit or delivery tool times out:
- keep the reranked baseline;
- show the best matching items;
- omit the live confirmation claim;
- record the enrichment timeout in the trace.
That is better than stalling the whole request until every enrichment call finishes.
Monitoring signals for this example
For this specific flow, I would monitor:
- rewritten-vs-original query delta for retrieval quality;
- top-K enrichment timeout rate;
- invalid-parameter rate on enrichment tools;
- reranker feature coverage after enrichment;
- fallback rate on live delivery or cabin-fit checks;
- p95 latency delta between enriched and tool-free paths;
- token growth and cost per successful session against the baseline path;
- claim suppression rate when live checks are unavailable.
If those signals move together, you can usually tell whether the regression started in interpretation, retrieval, reranking, or the tool path itself.
A common failure pattern in practice
A failure pattern I have seen more than once is partial enrichment that biases order without clearly breaking the page. Fresh inventory or delivery signals arrive for only part of the top candidates, feature coverage drops, and the reranker starts rewarding the presence of live features over raw relevance. Offline metrics may barely move while session conversion and claim suppression drift in opposite directions. The fix is usually to freeze the reranked baseline, default missing live features explicitly, and replay the affected sessions before widening rollout.
Failure modes that break search quality first
| Failure mode | Symptom | Why it happens | Mitigation |
|---|---|---|---|
| Tool spam | Tool-call rate, token usage, and p95 rise without better relevance | Tools become the default path instead of an escalation path | Enforce bounded tool placement, tool_choice, allowlisting, and per-request tool budgets via the OpenAI function calling controls |
| Latency explosion | p99 grows, cancellations rise, and downstream pressure spreads | Multi-hop tool chains multiply tail latency and retries | Propagate deadlines, cap retries, and follow the Google SRE guidance on cascading failures and overload handling |
| Retrieval drift | Offline retrieval metrics look different after query interpretation changes | Rewriting changes what the retriever is actually solving for | Log original and interpreted queries, evaluate both, and gate rollout on rewritten-vs-original deltas |
| Reranking distortion | Items with successful enrichments outrank more relevant items with missing features | Partial tool failures leak into reranking decisions | Use timeout budgets, default feature handling, and a deterministic fallback rerank path |
| Tool contract drift | Invalid-parameter rate rises, structured outputs stop matching downstream expectations, and reranker feature coverage drops | Tool description, schema, or output shape changed without replay tests or eval updates | Version contracts, validate outputs, pin schemas, and run per-tool replay tests before rollout |
| Authorization drift | Missing or inconsistent results, approval-denial spikes, or unexplained access mismatches across environments | Scope changes, token audience bugs, approval path regressions, or MCP trust misconfiguration | Separate read and write scopes, validate token audience, log approvals and denials, and run auth regression tests per tool |
| Reasoning-budget creep | p95, token usage, and cost per successful session rise without meaningful quality gain | Planning or tool escalation quietly becomes the default path instead of the exception path | Cap reasoning effort, cap tool-call budgets, and compare enriched and baseline paths at session level |
| Indirect prompt injection | Retrieved content shapes tool parameters or triggers unsafe actions | Search corpora often contain untrusted text | Treat retrieved text as untrusted and apply the controls described in NIST’s Generative AI Profile and OpenAI’s agent safety guidance |
Tools should be an escalation path, not the happy path.
Release discipline: stage 0 to stage 3
Stage 0. Keep a tool-free baseline
The baseline retrieval and reranking path must remain restorable at all times.
Acceptance rule: the team can force a no-tool path quickly and recover stable search behavior without redesigning the system.
Stage 1. Add one bounded tool role
Start with one of these:
- structured pre-retrieval interpretation; or
- post-ranking top-K enrichment.
Acceptance rule: the system can show where tool use begins and ends for that role, and its failure mode is understood.
Stage 2. Add trace-based evals and release gates
Before broader rollout, add blocking gates for:
- retrieval quality;
- reranking quality;
- tool-call rate;
- tool timeout rate;
- fallback rate;
- latency overhead;
- cost per successful session.
Acceptance rule: the team can tell whether a regression came from retrieval, reranking, or tool behavior.
Stage 3. Add action tools behind approval
Only after the read path is stable should the system execute actions. Even then, high-impact tools stay behind approval or equivalent policy enforcement.
Acceptance rule: the action path has per-tool flags, traceability, approval boundaries, and rollback discipline separate from the answer path.
This sequence is less dramatic than a full agent launch, and that is exactly why it survives production.
Practical checklist
Before calling a search system production-ready and agentic, I would want the list below to be true.
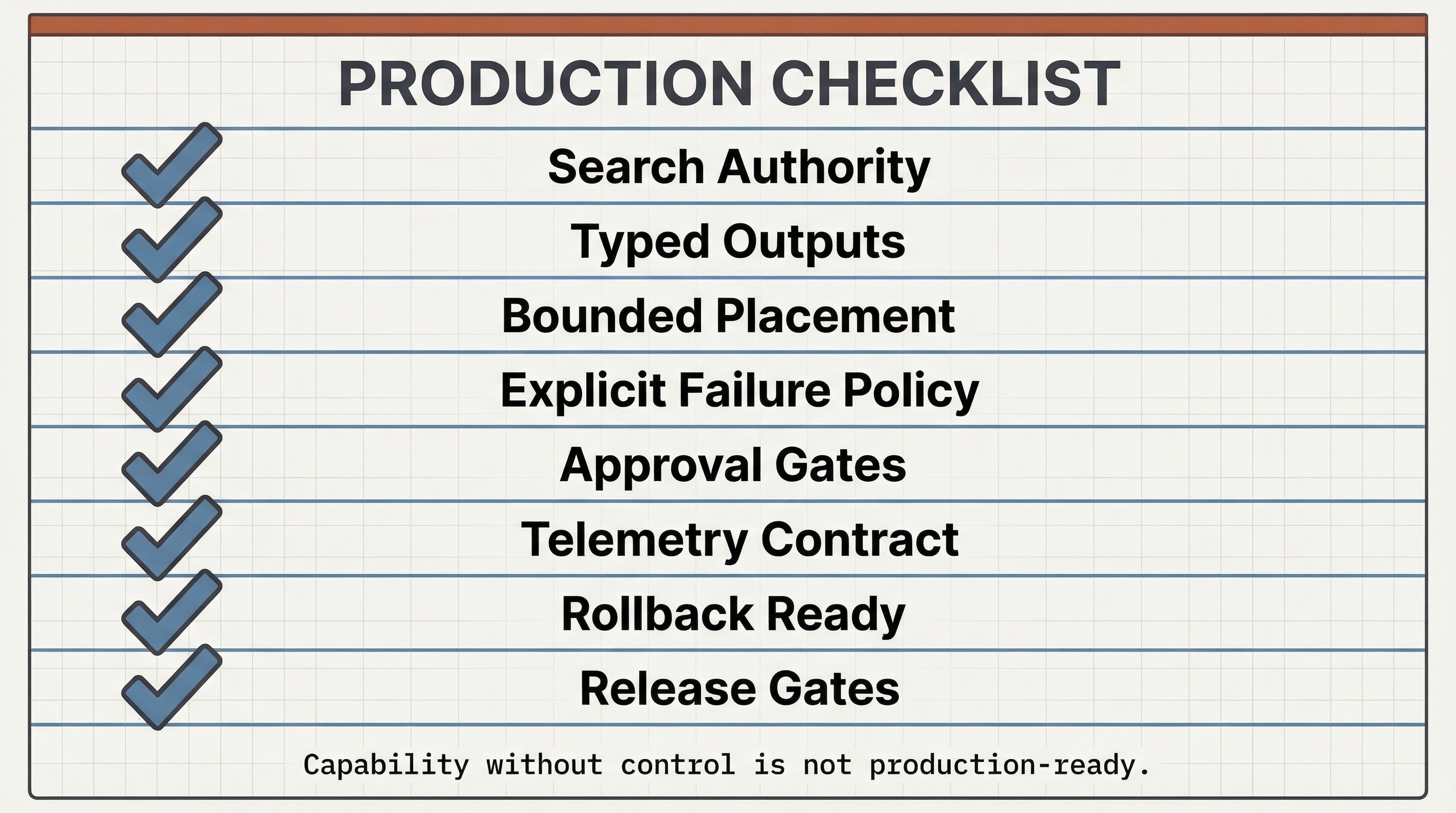
Compact checklist for deciding whether a search system is ready for bounded tool use.
- Retrieval and reranking remain the primary authority for result selection.
- Tool calling has a documented role: interpretation, enrichment, or approved action.
- Tool outputs enter the stack as typed features, bounded evidence, or explicit approval state.
- Every tool has a strict input schema, strict output schema, timeout, owner, and review path.
- Failure policy is explicit: fail open or fail closed by tool role.
- The runtime has hard budgets for tool-call count, token growth, and latency overhead.
- Retrieved content is treated as untrusted at the tool boundary.
- Risky tools require approval or equivalent policy checks.
- The tool-free baseline can be restored immediately.
- Traces connect queries, retrieval, reranking, tool calls, auth state, and outcomes.
- Release gates use both search metrics and tool metrics.
- Ranking regressions and tool regressions can be separated during incident review.
If the gain from tool use is smaller than the loss in control, you added complexity, not capability.
Final point
Tool calling becomes valuable in search only when it stays subordinate to the search contract.
Retrieval defines the evidence space.
Reranking defines the product contract.
Tools may interpret, enrich, or act, but they must not silently override the search contract.
The production question is simple: did tool use improve coverage or actionability without taking away relevance, latency discipline, safety, or rollback control?
If the answer is not clearly yes, the system is harder to operate, not more capable.
In search, uncontrolled tool use is not autonomy. It is hidden ranking policy.
Further watching
If you want a few companion sessions without turning the page into a media wall, these are the ones worth opening next.
- Building Blocks for Tomorrow’s AI Agents: Anthropic on practical building blocks for bounded agent systems.
- Model Context Protocol: how MCP went from blog post to the Linux Foundation: GitHub on MCP standardization and governance across the ecosystem.
- How to secure your AI Agents: A Technical Deep-dive: Google on agent security, authorization boundaries, and MCP-related risks.
Standards and references
- OpenAI Function Calling Guide (retrieved March 21, 2026)
- OpenAI Trace Grading Guide (retrieved March 21, 2026)
- OpenAI Agents SDK Tracing (retrieved March 21, 2026)
- OpenAI Safety in Building Agents (retrieved March 21, 2026)
- OpenAI MCP and Connectors Guide (retrieved March 21, 2026)
- Anthropic: Writing Tools for Agents (October 8, 2025)
- AWS OpenSearch: Agentic Search (retrieved March 21, 2026)
- OpenSearch 3.2: Agentic Search (retrieved March 21, 2026; experimental and not recommended for production in OSS 3.2)
- Azure AI Search: Agentic Retrieval Overview (retrieved March 21, 2026)
- Azure AI Search: Create a Knowledge Base (retrieved March 21, 2026; preview, no SLA, not recommended for production workloads)
- Azure AI Search: Set Retrieval Reasoning Effort (retrieved March 21, 2026)
- Model Context Protocol Specification 2025-11-25
- Model Context Protocol Schema Reference 2025-11-25 (retrieved March 21, 2026)
- OpenTelemetry GenAI Semantic Conventions (retrieved March 21, 2026; current status: Development)
- OpenTelemetry GenAI Metrics (retrieved March 21, 2026; current status: Development)
- OpenTelemetry MCP Semantic Conventions (retrieved March 21, 2026; current status: Development)
- NIST AI 600-1: Generative AI Profile (July 26, 2024)
- OWASP: Securely Using Third-Party MCP Servers (November 4, 2025)
- OWASP: Secure MCP Server Development (February 16, 2026)
- Google SRE: Addressing Cascading Failures (retrieved March 21, 2026)
- Google SRE: Handling Overload (retrieved March 21, 2026)
- SoK: Agentic RAG (March 7, 2026)
- Is Agentic RAG Worth It? (January 12, 2026)
FAQ
What is agentic search in a production retrieval stack?
It is a retrieval and reranking system with bounded tool use. Search remains the authority for evidence and ordering, while tools are added only for interpretation, enrichment, or approved actions.
What is the safest way to place tool calling in a search stack?
Keep retrieval and reranking as the primary authority, then add tool calling only in bounded roles such as structured query interpretation, top-K enrichment, or approved actions.
When should tool calls happen before retrieval versus after reranking?
Before retrieval, use tools only for narrow interpretation tasks such as permissions or filter construction. After reranking, use them for top-K enrichment, fresh feature fetches, or bounded action steps.
Should tool outputs ever change final ordering in search?
Only as typed features under explicit ranking policy. Tool outputs should not become a free-form authority layer that silently overrides retrieval or reranking.
Which metrics show that tool use is hurting search quality?
Watch rewritten-vs-original query deltas, reranker win-rate drops, tool timeout rate, fallback rate, tool-call rate, and latency overhead alongside the main retrieval and business metrics.
How should MCP tools be governed in production search systems?
Pin the protocol version, treat remote tool boundaries as trust boundaries, keep read and write scopes separate, require approvals for high-impact actions, and log every tool path for review and rollback.