Voice AI Operator for Contact Center
An on-prem voice AI operator for a financial contact center that automated 72% of inbound calls, reduced cost per call by 58%, and stayed inside strict compliance boundaries.

One-liner: This on-prem voice AI operator automated 72% of inbound calls, cut cost per call by 58%, and kept a regulated contact center inside latency, auditability, and human-oversight constraints.
Executive summary
The client was a financial services contact center with about 600 seats, roughly nine minutes of queue time during peak periods, and a large concentration of repetitive inbound questions. Balance checks, refund status, and card-blocking flows consumed human capacity even though the interaction patterns were narrow enough to automate safely. At the same time, new compliance pressure made a cloud-first voice bot strategy difficult to defend. The system needed to move fast, but it also needed to stay legible to risk, security, and operations.
The final architecture was an on-prem voice AI operator built around streaming speech recognition, a two-stage model cascade, a grounded knowledge path, explicit safety scoring, and deterministic human escalation. It automated 72% of calls without a human agent, reduced queue time from 9.0 minutes to 2.4 minutes, lowered cost per call from $3.90 to $1.64, and delivered about $420,000 in annual savings.
| Metric | Before | After | Why it moved |
|---|---|---|---|
| Queue time | 9.0 min | 2.4 min | Routine intents no longer waited for live-agent capacity |
| Auto-resolve rate | 21% | 72% | Streaming AI handled the repetitive path and escalated only when necessary |
| Cost per call | $3.90 | $1.64 | On-prem serving and model cascade reduced expensive human and compute overhead |
| v2v p95 | not productionized | 1.42 s | A tight runtime budget kept the voice experience usable |
| CSAT | 3.6 | 5.5 | Faster answers and cleaner escalation improved the customer experience |
| Regulator complaints | 11 / quarter | 0 | Explainability, logging, and human control were built into the contract |
This case sits at the intersection of runtime systems and operating control. For the orchestration side, the closest conceptual companion is Agent vs. Workflow: Architecture Framework. For the production discipline side, it aligns closely with MLOps for a Support RAG Agent in 2026 and the broader MLOps and Reliability topic cluster.
Why the project mattered
This was not a “replace the call center” project. It was a production operations project under regulatory pressure.
- The center had 600 seats but still exposed customers to multi-minute waits.
- About 64% of inbound issues were repetitive enough to automate if the system stayed grounded and safe.
- Policy and product guidance changed faster than teams could retrain human agents.
- AI governance requirements meant that every automated answer needed a credible explanation and a human fallback.
That combination creates a narrow design space. A generic chatbot is too loose. A classic IVR is too limited. The system needed real-time speech, bounded reasoning, grounded answers, explicit control, and a clean handoff path.
Success criteria
The project was measured against hard operational targets, not qualitative demo feedback.
| Metric | Target | Result |
|---|---|---|
| Auto-resolve rate | at least 65% | 72% |
| Voice-to-voice p95 | at most 1.5 s | 1.42 s |
| Cost per call | down 50% | down 58% |
| CSAT | +1.5 points | +1.9 |
| Regulator complaints | zero | 0 |
| Handoff p95 | at most 5 s | at or below 5 s |
Those targets shaped the architecture directly. The system could not afford a slow “reasoning” loop. It needed a fast-path answer model, a slower model for harder cases, tight decision boundaries, and operator escalation as a first-class part of the product.
System design

Runtime map of the real-time path: intake, ASR, routing, grounded answer generation, and escalation outcome.
The runtime had five major stages.
1. Inbound call and transport
Calls entered through SIP / WebRTC integration and were normalized into the voice pipeline. This stage sounds boring, but transport stability is what determines whether the rest of the ML system even gets to matter.
2. Streaming ASR
Whisper v3 streaming handled live speech recognition. The design target was to keep partial recognition useful enough for early routing signals while holding ASR latency in the low hundreds of milliseconds. In the measured runtime, ASR averaged about 180 ms and stayed around 220 ms at p95.
3. Intent and knowledge path
The system routed requests through an intent layer plus a grounded retrieval path. For simple account and service requests, the assistant could respond on the fast path. For more complex or policy-sensitive cases, it pulled evidence from the internal knowledge base through Qdrant-backed retrieval before composing a response.
4. Model cascade
The model path was deliberately split:
- Llama 3.1 8B INT4 handled the routine path
- Llama 3.1 70B NF4 handled harder cases
This was the economic core of the system. The fast model absorbed the high-volume repetitive distribution. The larger model was invoked only when the lower-cost path could not safely answer with enough confidence.
5. TTS or human handoff
The answer was synthesized back into speech or routed to a human operator. If the AI path could not satisfy confidence, policy, or grounding rules, it escalated. Handoff was not a failure case. It was part of the designed service contract.
Why on-prem was non-negotiable
The decision to keep the stack on-prem was not ideological. It came from the risk model.
- The client could not send PII and audio freely outside the security perimeter.
- Auditability, retention, and DSAR workflows had to be explicit.
- Risk and security teams needed to understand which components touched customer data.
- Human oversight had to stay enforceable during live interactions, not only after the fact.
The production answer was an on-prem media and control plane, with regulated data kept inside the environment. That made the system harder than a pure API integration, but it also made it deployable in the first place.
Control, safety, and escalation

Control loop for disclosure, grounding, risk checks, and explicit operator escalation.
The assistant operated under a very plain control model:
- every automated interaction started with AI disclosure
- the system never answered without a grounded source path for policy or knowledge questions
- PII stayed on-prem
- human escalation was always available by request
- unsafe, low-confidence, or policy-violating sessions were escalated automatically
The risk score used a weighted combination of toxicity, low confidence, and policy violation signals. Anything above threshold, or any case with repeated ASR failure, missing evidence, or explicit operator request, went to a human.
This is the production version of what many voice AI projects miss: the automation path and the escalation path are part of the same architecture. If the escalation path is weak, the automation path is not safe no matter how good the demo sounds.
Operational evidence
The runtime data is what makes this a real case study rather than a conceptual system.
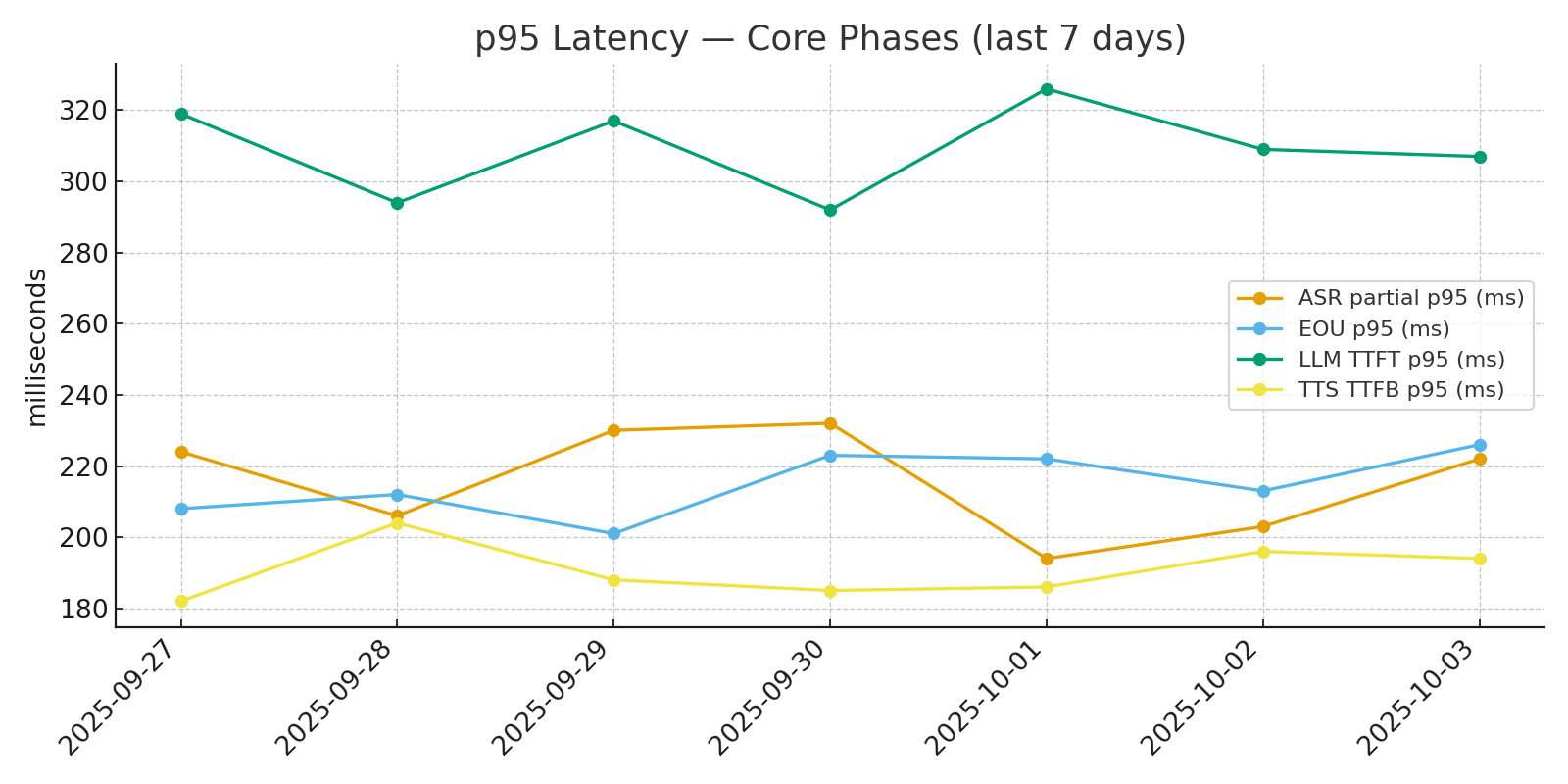
Core runtime stages were tracked as separate latency budgets rather than one blended “response time” number.
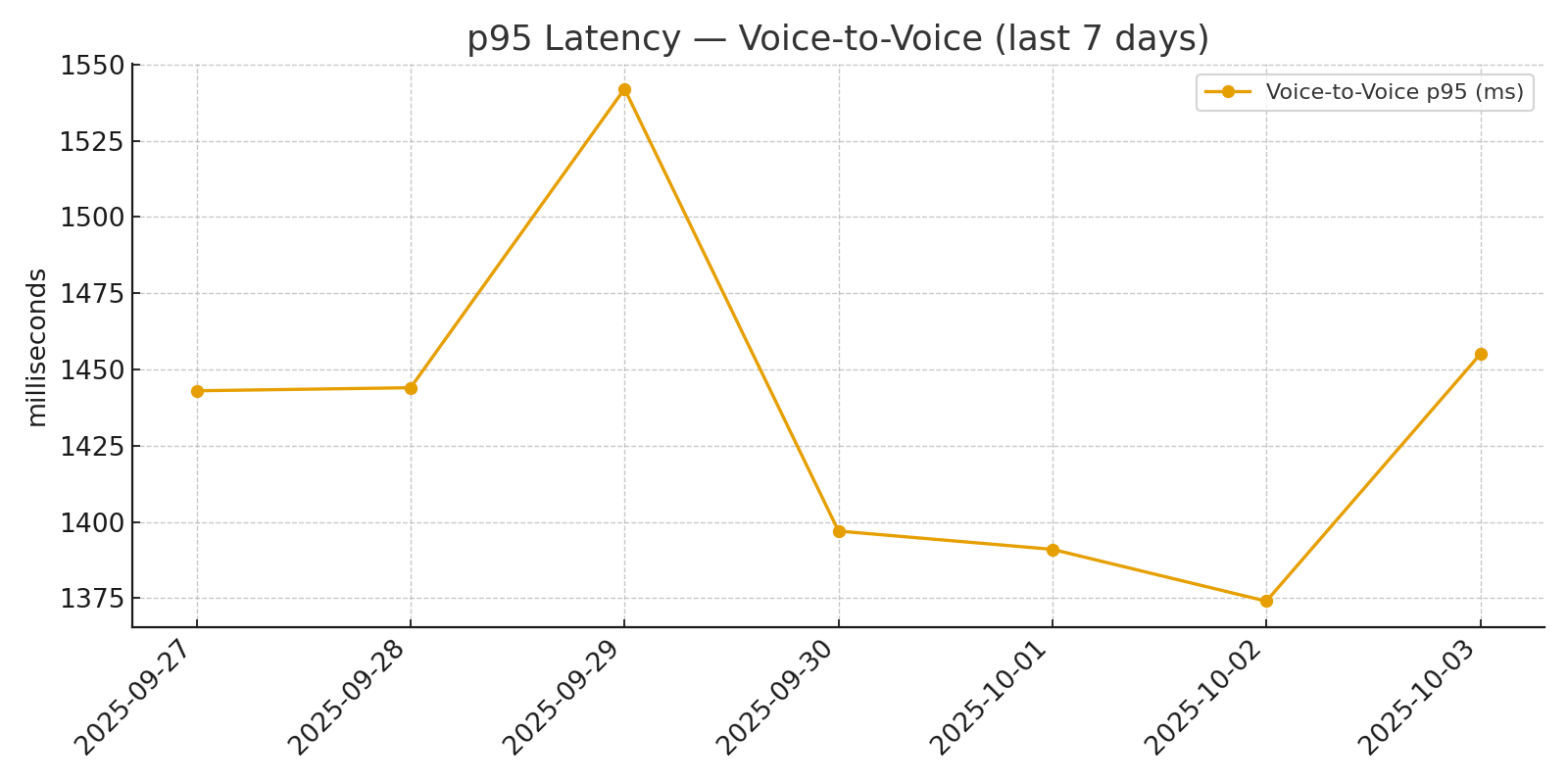
Voice-to-voice p95 stayed within the target operating envelope after warm-up, which is what made the assistant usable in a live contact-center setting.
The measured latency budget looked like this:
| Stage | Target | Observed average / p95 |
|---|---|---|
| ASR | <= 200 ms | 180 / 220 ms |
| End-of-utterance | <= 250 ms | 160 / 212 ms |
| Time to first token | <= 300 ms | 240 / 310 ms |
| Voice-to-voice | <= 1,500 ms | 960 / 1,420 ms |
That budget matters because customers do not experience the system as a single model call. They experience a chain. If any one stage drifts far enough, the entire service becomes frustrating.
Economics
The system reduced cost per call from $3.90 to $1.64, a 58% improvement.
That result came from three levers working together:
- more routine calls resolved without a human
- a cheaper model path for the majority of traffic
- an on-prem serving model that avoided a permanent per-call cloud premium
The economic model was also stress-tested rather than presented as one static average.
- If complex intents increased by 30%, cost per call rose to about $1.89.
- If one GPU server was unavailable, cost per call rose to about $1.97.
That is the right way to talk about AI economics in production. The average number matters, but so do the failure envelopes.
Compliance model
The compliance layer was operational, not decorative.
| Control | How it worked in production |
|---|---|
| Transparency | The system disclosed that the caller was interacting with an AI operator |
| Retention | Logs were stored for 180 days, with controlled deletion workflows |
| DSAR | Data subject access and deletion requests were handled within 96 hours |
| Human oversight | The customer could request an operator, and high-risk cases were escalated automatically |
| Explainability | Responses were tied to source documents and logged alongside prompt context |
| Restricted capabilities | Emotion recognition and biometric analysis were excluded by policy |
This is what made the drop in regulator complaints credible. The system was not simply more polite or faster. It became more auditable.
Reliability, fairness, and resilience
The team did not stop at latency.
Quality and resilience controls included:
- 5% sampled call review
- nightly adversarial evaluation across 320 scenarios
- alerting on TTFT drift, dropout spikes, and hallucination flags
- fairness review across accent clusters
- tested fallback behavior under network loss and GPU degradation
The fairness view was especially important because the assistant handled spoken language under different accent conditions.
| Accent cluster | WER before | WER after | Intent accuracy |
|---|---|---|---|
| Central Russian | 6.2% | 5.8% | 94.1% |
| Southern / Caucasus Russian | 9.5% | 7.1% | 91.3% |
| English with accent | 12.8% | 9.4% | 88.0% |
The system also remained serviceable under degraded conditions. At 20% packet loss, voice-to-voice p95 was about 1.55 seconds. During GPU outage, the runtime fell back to the 8B path and held the service inside the broader SLA envelope.
My role
I led the core ML and MLOps architecture for the system:
- designed the streaming runtime around the voice-to-voice latency budget
- introduced the model cascade that materially reduced token and runtime cost
- built the RAG-backed answer path and grounded-response rules
- owned the observability layer and incident response instrumentation
- translated compliance requirements into runtime behavior instead of documentation-only controls
This was not a prompt design task. It was a production systems task with model, infrastructure, policy, and reliability boundaries all tied together.
Technical annex
Capacity and runtime envelope
Peak capacity was designed around about 180 concurrent calls.
| Resource | Service | Concurrency / throughput | p95 |
|---|---|---|---|
| A100 80GB pair | Llama 3.1 70B | up to 3 sessions per pair | 1.42 s |
| A100 80GB slice | Llama 3.1 8B | about 6 sessions per slice | 0.98 s |
| L40S | Whisper v3 | up to 40 channels | 0.22 RTF |
| L40S | TTS synthesis | up to 35 streams | 168 ms TTFB |
Knowledge path and orchestration
The knowledge plane pulled from internal sources such as Google Drive, Jira, and Confluence through sync jobs and versioned updates. Documents were chunked, embedded, and upserted with source tracking. Temporal handled orchestration, retries, and service-tool sequencing. The knowledge path used top-k retrieval, reranking, and citation retention so that the assistant could explain where an answer came from.
SLO and error-budget policy
The main runtime SLOs were:
- voice-to-voice p95 <= 1.5 s
- dropout rate <= 2%
- handoff latency <= 5 s
- hallucination flags <= 1% of dialogs
Burn-rate alerts at 2x threshold were allowed to stop rollout automatically.
Security perimeter
The media plane ran inside the internal segment, audio was stored in encrypted form, the control plane used Zero Trust controls with mTLS and OIDC, secrets were managed through Vault with scheduled rotation, and the Genesys on-prem integration was restricted through mTLS and allowlists.
What this case proves
This project proves that voice AI in a regulated contact-center environment can be both useful and governable if the architecture is built around control instead of novelty.
The key lesson is simple: production voice AI is not one model. It is a contract across transport, ASR, routing, grounding, synthesis, safety, escalation, observability, and compliance. When those pieces are designed together, automation stops being a risk experiment and becomes a real operating capability.
Bottom line
The system improved customer wait time, reduced operating cost, protected compliance posture, and kept a human fallback where it belonged. That is why this case matters. It shows what a real voice AI operator looks like when it is designed for a boardroom, an SRE review, and a regulator at the same time.
FAQ
Why was this deployed on-prem instead of as a cloud voice bot?
The client needed tighter control over PII, auditability, retention, and human oversight. On-prem deployment kept the media plane and regulated data inside the perimeter while still allowing modern model orchestration.
What actually drove the 58% cost-per-call reduction?
Most of the savings came from automating routine intents through a fast-path model, reducing handoffs, and keeping inference on an optimized on-prem stack instead of paying a cloud premium on every interaction.
How was compliance handled without freezing delivery speed?
Compliance was treated as part of the runtime contract: AI disclosure, source-grounded answers, retention rules, operator escalation, risk scoring, and auditability were designed into the system instead of added after launch.
