Evals for LLM Agents: The Minimal Production Set
TL;DR: Agent evals are an engineering control loop with the same status as tool contracts and observability. The working minimum has five parts: a capability suite for target scenarios, a regression suite built from real incidents, trajectory checks at the tool-call level, a calibrated LLM-as-judge, and online monitoring on a traffic sample. Reliability is measured with pass^k, economics with cost_per_success, releases are blocked by gates when thresholds are violated, and production logs and incidents feed new tasks into the suite.
Teams argue enthusiastically about model choice and orchestration frameworks, but rarely pin down the answer to the central question: how exactly does the system learn that the agent got worse. Without evals the answer looks like “users complained” or “an incident on Friday night”. Both options are expensive: industry surveys from 2025-2026 list quality as the number one barrier to shipping agentic systems, and a significant share of projects gets cancelled before release precisely because quality stays unmanaged.
This article covers the practical frame: which failure classes exist, which graders catch them, which metrics measure reliability, how an eval harness is built, and how to assemble the loop an agent should not ship without. It complements the agent vs workflow decision framework: that article answered the architecture question, this one answers how to control the quality of the chosen architecture.
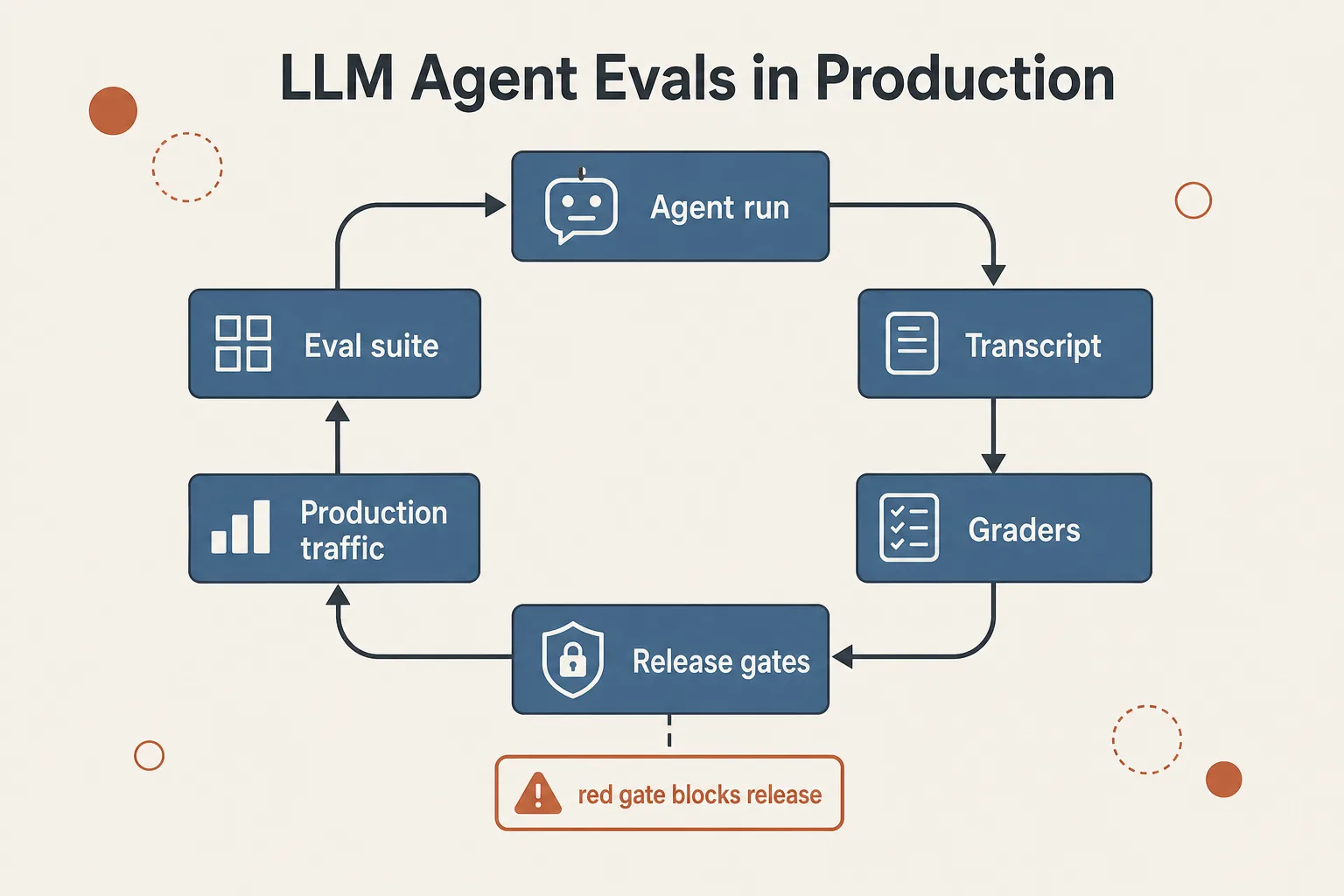
A closed quality loop: the eval suite feeds runs, graders feed gates, and production returns new tasks into the suite.
How to read this article
- If you need the minimal set composition: the sections on the five components and the harness architecture.
- If you need metrics for release decisions: the sections on pass@k, pass^k, and release gates.
- If trust in the model judge is the pain point: the LLM-as-judge calibration section.
- If a suite already exists but goes stale: the sections on production-log mining and the pre-release checklist.
Vocabulary: four terms that remove the noise
Eval discussions often stall on terminology. Four definitions are worth fixing upfront.
- Task: a concrete scenario with input, environment, and success criteria. For example: “the user requests an order refund, the agent must process the return without exposing another customer’s data”.
- Trial: a single run of the agent on a task. Because models are stochastic, each task is run multiple times.
- Transcript (also trace or trajectory): the observable record of a trial: messages, tool calls with arguments and results, retrieved context, intermediate artifacts, and the final answer. Hidden model reasoning is often unavailable for logging or deliberately not logged in modern systems, so the evaluation loop is built on the observable trace and must not depend on internal chain-of-thought.
- Grader: logic that scores some part of the transcript or the outcome. A single task can have multiple graders, each with multiple checks.
Fixing these terms immediately separates two different questions: “did the agent solve the task” and “did the agent solve it in an acceptable way”. A production system must answer both.
Failure map: what evals are supposed to catch
Before building the suite, it pays to fix what it protects against. Each failure class is caught by a specific component of the loop, and this is the main argument against cutting the composition down.
| Failure class | How it looks in the product | How it looks in metrics | Which component catches it |
|---|---|---|---|
| Wrong tool selection | Agent answers from memory instead of calling the API | tool_call_recall drops |
trajectory checks |
| Argument drift | Calls stop passing validation after a prompt change | schema violations grow | trajectory checks |
| Loops and wasted iterations | Task takes 14 steps instead of 4 | steps_per_success and cost grow |
trajectory checks |
| Ignored tool results | Agent gets data, then answers from hallucinated memory | judge groundedness diverges from outcome | judge + trajectory |
| Unsafe intermediate step | Final answer correct, but foreign data was read on the way | allowlist violations with green outcome | trajectory checks |
| Long-horizon decay | Quality drops after the N-th turn of a dialog | pass rate drops on multi-turn tasks | capability suite |
| Silent regression after a model update | The provider updates the model, behavior drifts | red regression with green demos | regression suite |
| Judge drift | Judge scores diverge from human labels | judge_agreement drops |
judge calibration |
The rows make a useful design checklist: if no component catches a given failure class, that failure will be discovered by a user.
Two evaluation levels: outcome and trajectory
Outcome evaluation answers the product question: was the task solved or not. The refund was processed, the ticket was created, the answer is correct. This level is mandatory but insufficient.
Trajectory evaluation answers the engineering question: why did the agent do what it did. It inspects intermediate steps: tool selection, call arguments, result utilization, loops, and wasted iterations. This is where degradations hide that outcome metrics mask: the agent solves a task in 14 calls instead of 4, ignores a tool result and relies on hallucinated memory, or takes an unsafe intermediate step while producing a correct final answer.
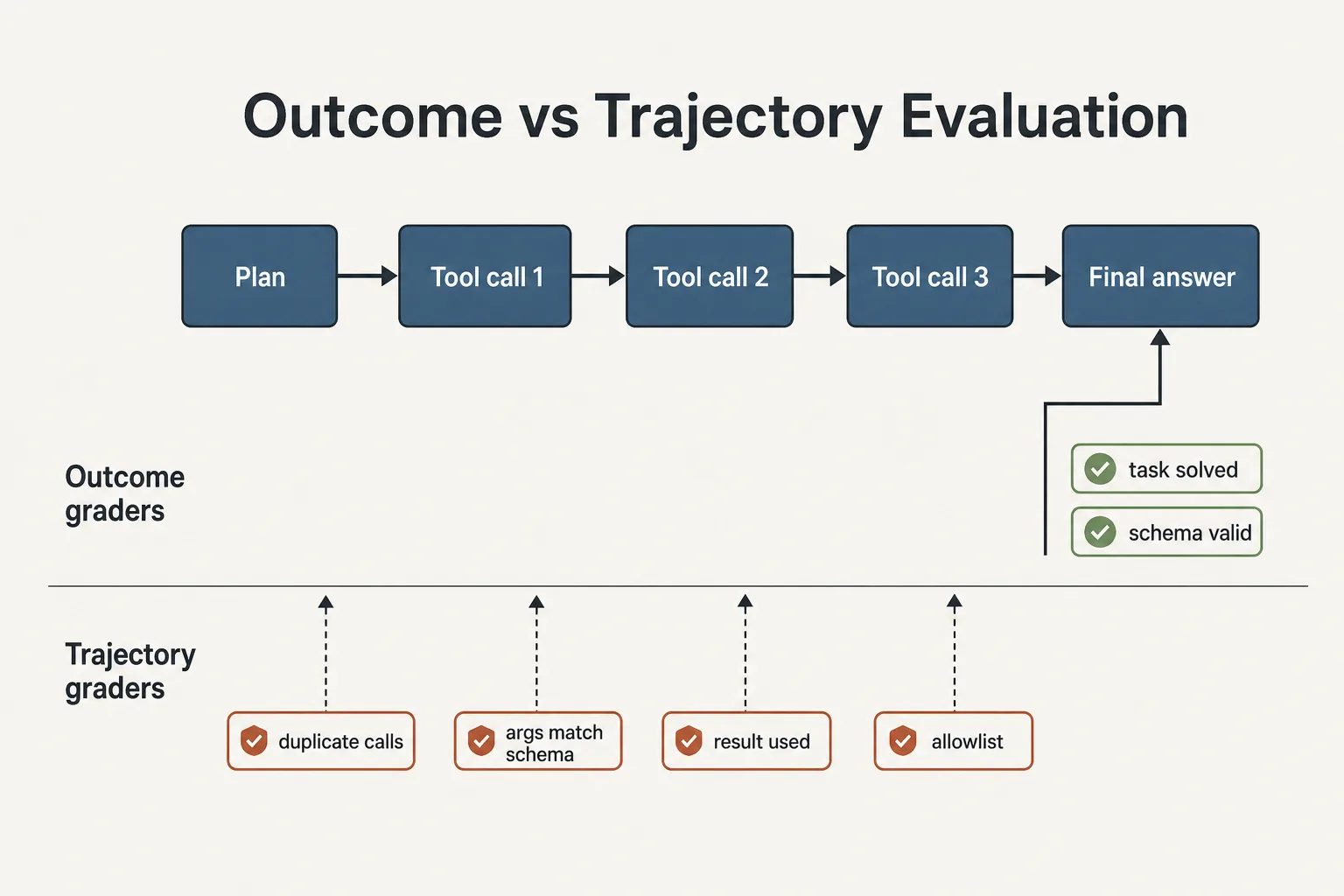
Outcome graders score the final state, trajectory graders score the path: duplicate calls, argument schemas, result usage, and the allowlist.
The practical consequence: both levels run in parallel. Outcome decides whether you can release. Trajectory decides where to fix and what will become an incident a month later.
Grader types and when to use each
Agent evals combine three grader types. The order of preference is fixed: deterministic checks wherever possible, model-based where determinism is unreachable, human graders sparingly for calibration.
| Type | What it checks | Strengths | Limitations |
|---|---|---|---|
| Code-based | Schemas, statuses, tests, regex, latency, call budgets | Cheap, fast, reproducible | Covers only formalizable properties |
| Model-based (LLM-as-judge) | Answer quality, groundedness, tone, completeness | Scales to subjective criteria | Needs calibration, can fail systematically |
| Human | Ambiguous cases, golden labels | Source of truth for calibration | Expensive, slow, does not scale |
Per task, scores combine in one of three modes: binary (all graders must pass), weighted (the combined score must clear a threshold), or hybrid. For side-effect actions only binary mode is acceptable: a partially correct refund is an incident, not a 0.7 score.
A separate requirement for any grader: resistance to gaming. If the agent can pass a check without solving the task, the metric measures the quality of the loophole. Graders should be designed so that passing genuinely requires solving the problem: verifying the environment state after the run is more reliable than verifying the answer text.
A detailed treatment with example eval specs is in Anthropic’s engineering article Demystifying evals for AI agents. It deserves a full read: it is one of the few texts that covers graders at the level of practice rather than slogans.
The minimal production set: five components
Below is the composition that covers baseline quality control for an agent. Cutting it down is risky: the failure map above shows which problem class becomes invisible when each component is dropped.
1) Capability suite
Tasks across the target scenarios of the business function, with unambiguous success criteria. A working starting point is 20-50 tasks, but that is a heuristic rather than a standard. A narrow scoped agent needs fewer; a critical enterprise function will need hundreds, and the real size is determined by coverage of the failure map, not by a round number.
A good task passes the two-expert test: both independently reach the same pass/fail verdict. If experts disagree, the task produces noise instead of signal and needs refinement.
Each task should have a reference solution: a known good run that passes all graders. This proves the task is solvable and the graders are configured correctly. A zero pass rate across dozens of trials almost always means a broken task rather than a weak agent: typical causes are an ambiguous spec, a grader with an overly rigid format check, or an environment where the task is physically unsolvable.
The suite is stratified by criticality: critical scenarios (money, access, irreversible actions) get more tasks and more trials than peripheral ones.
2) Regression suite
Every production incident and every confirmed bug becomes a regression task. Over time, capability tasks with high pass rates also “graduate” into regression: their question changes from “can we do this at all” to “can we still do this reliably”.
The regression suite runs on every change: a new prompt, a new model version, a new tool, a change in context assembly. It is the first line of defense against silent degradation, including the case where the provider updates the model behind the same name.
3) Trajectory checks
The minimal set of deterministic checks over the transcript:
- tool call arguments match the target JSON schema;
- no duplicate calls to the same tool with the same arguments;
- iteration and token budgets per task;
- tool results are actually used in the next planning step;
- no calls outside the allowlist and no access to forbidden resources.
The contract side of this list was covered in the article on tool calling in a search system: weak contracts at the tool boundary remain the main source of agent incidents.
4) Calibrated LLM-as-judge
A model judge evaluates what code cannot formalize: answer completeness, groundedness of claims, communication quality. The rules that separate a working judge from a random score generator are collected in a dedicated section below.
5) Online monitoring
An offline suite does not cover real traffic drift. So the same graders run asynchronously on a sample of live sessions: typically 1-10% of traffic without blocking the user-facing response. The key requirement: the judge rubric and thresholds match the offline loop, otherwise pre-launch and post-launch numbers cannot be compared.
Sampling should be stratified: critical scenarios and escalated sessions enter the sample with higher weight. A uniform sample across all traffic overestimates easy scenarios and misses degradation in the expensive ones.
Eval harness architecture
The five components run on shared infrastructure. The minimal architecture looks like this:
Task Store ----> Environment ----> Runner ----> Transcript Store ----> Grader Pool ----> Report / Gates
(specs, Manager (agent, (observable (code checks, (dashboards,
fixtures, (state reset, pinned traces, judges, run diffs,
reference frozen clock, versions, OTel attributes, metrics) CI status,
solutions) tool sandbox) parallelism) retention) alerts)
^ |
| v
Production Logs <---- Incident / Feedback Mining <---- Online MonitoringComponent by component: what each one must be able to do, and where teams most often cut the corner they later pay for.
Task Store: tasks as code
Task specs live in the repository and go through review like regular code: version, owner, change history. Changing a task’s success criteria is a change to the quality contract, and it should be visible in a diff rather than silently happening in an admin panel.
Fixtures and the reference solution are versioned together with the spec. Without this it is impossible to answer the question “did the metric drop because the agent got worse, or because someone changed the task”.
Environment Manager: determinism as a contract
If the environment drifts, the metrics measure the environment. Minimal requirements:
- fixtures with fixed state and an explicit version;
- a frozen clock: tasks with deadlines and schedules must not depend on the run date;
- full state reset between trials: shared state turns independent runs into dependent ones;
- pinned tool versions inside the sandbox.
For the tools themselves there are three modes with different trade-offs. Mocks are cheap and fast but hide contract mismatches with the real API. Staging tools are more honest but slower and require data isolation. Replay mode, where recorded responses from real APIs are played back, offers a balance: honest contracts with determinism and zero load on external systems. The working combination: mocks or replay in the per-commit smoke suite, staging in the nightly full run.
Runner: versions nailed down
An eval run result is only meaningful as a point in version space. The minimal tuple stored with every run:
run_id
agent_version # orchestrator code
prompt_version # system prompt and templates
model_id + snapshot # exact model version, never a "latest" alias
tools_version # tool contract versions
fixtures_version # environment state
grader_versions # versions of all graders and rubrics
judge_model_id # judge model pinned separately from the agent modelIf even one field is not pinned, comparing two runs loses meaning: a metric delta cannot be attributed to a specific change. Aliases like “latest” are banned in the runner for the same reason they are banned in production deploys.
The runner also owns parallelism with cost caps, per-trial timeouts, and the distinction between retries and trials: a re-run caused by an infrastructure error (API timeout, a 500 from the sandbox) does not count as a failed trial and is flagged separately.
Transcript Store: the observable trace as a first-class artifact
The run record is stored in the same format as production traces. For agent systems the OpenTelemetry GenAI semantic conventions keep eval results and live traces in one coordinate system, so a grader from CI works unchanged on the production sample.
The observable trace contains: messages, tool calls with arguments and results, retrieved context, intermediate artifacts, the final answer, per-step timings and cost. Hidden model reasoning is deliberately excluded from this contract: it is not always available, its format is not stable across model versions, and a grader that depends on internal chain-of-thought will break on the provider’s next update.
Retention and access are fixed explicitly: transcripts contain fixture data and potentially fragments of production cases, so the store inherits the same rules as logs with user data.
Grader Pool: graders decoupled from the runner
A stored transcript can be re-scored with a new grader version without re-running the agent. This makes rubric iteration dramatically cheaper: revising a threshold or a wording does not burn run budget, and history can be recomputed retroactively to see how the new rubric would have scored past releases.
The design consequence: a grader receives only the transcript and the post-run environment state as input. A grader that needs live access to the agent is designed wrong.
Report and gates: the diff matters more than the snapshot
An aggregated run metric hides the structure of the change. A working report compares two runs at the task level: which tasks flipped from pass to fail, which flipped from fail to pass, where variance grew. A release that raised the average pass rate by two points while breaking three critical tasks is visible only in such a diff.
So the minimal set of views: a daily trend, a task-level diff of two runs, a breakdown by scenario criticality, and run cost. That is enough for the gates in the section below to operate on data rather than impressions.
How many trials: statistics without illusions
Agent stochasticity makes a single run a meaningless measurement, but an unlimited trial budget is unnecessary. What matters is knowing exactly what each trial buys.
The error of a pass-rate estimate follows binomial statistics: the standard error is sqrt(p(1-p)/n). Concrete consequences:
- 5 trials on a single task with a true pass rate of 0.8 give a standard error of roughly 18 percentage points: at the task level only coarse states are distinguishable: consistently passing, consistently failing, unstable;
- 40 tasks with 5 trials each give 200 observations and a suite-average error of about 3 points: enough for trends and for gates with a margin from the threshold;
- halving the interval requires four times more runs, so “let’s add precision” is always expensive.
Three practical rules follow. First: a gate that compares a metric against a threshold must account for uncertainty. If the result lies within the error of the threshold, the decision is made by adding trials on the contested tasks rather than by a coin flip. Second: when comparing two agent versions, use paired comparison on identical tasks and fixtures: the per-pair delta has lower variance than the difference of two independent means and needs noticeably fewer runs for the same conclusion. Third: at small n, conservative estimates such as the Wilson interval are more correct, because the normal approximation on 5 trials overstates confidence.
The trial budget is allocated by criticality: 1-3 trials per task in the per-commit smoke suite, 5-10 trials on critical scenarios in the nightly run and before release, plus targeted extra trials wherever a metric sits at a gate threshold.
Unstable tasks are not deleted from the suite: a flaky task signals real agent instability on that scenario. It gets an owner and an investigation deadline, and until resolved it is reported as a separate line so it does not pollute the gates.
Reliability metrics: pass@k versus pass^k
The working metric pair for a stochastic system:
- pass@k: the probability of at least one success in k attempts. Fits tools where one good attempt solves the task: code generation with tests, exploratory research.
- pass^k: the probability of success in all k attempts in a row. Fits customer-facing agents where behavioral consistency matters.
The difference is fundamental. An agent with a 75% per-trial success rate yields pass^3 of about 42%: 0.75 cubed. For a customer-facing function this means more than half of users will hit at least one failure across three interactions. The outcome metric “75% of tasks solved” sounds acceptable; pass^k shows the real reliability picture. As k grows the metrics diverge in opposite directions: pass@k approaches 100% while pass^k falls toward zero, and the choice between them is a product requirement rather than a matter of taste.
The reliability pair is extended with economics and process metrics:
task_success_rate # outcome across target scenarios
pass^k # consistency over k trials
tool_call_precision # share of correct calls among calls made
tool_call_recall # share of required calls the agent actually made
steps_per_success # median steps to success
cost_per_success # full cost per successfully solved task
judge_agreement # judge agreement with human labelsThe cost formula is the same one used in the architecture decision article: the numerator collects LLM, tools, infrastructure, and human review; the denominator counts only successful tasks.
LLM-as-judge without self-deception
The model judge is the most common source of false confidence in agent systems. The naive scheme “ask the model to score from 1 to 10” produces scores that do not correlate with quality. The working rule set:
- Calibrate against humans before scaling. The judge runs on a golden dataset with human labels. A working agreement target is 75-90%, but that is a heuristic calibrated by the domain itself. On ambiguous tasks where even experts disagree, 75% may be the ceiling; on formalizable criteria, 90% is the floor. The honest procedure: first measure inter-expert agreement, then require a comparable level from the judge. A judge with unmeasured agreement is a noise generator with a confident tone.
- One judge per dimension. Instead of one score “for everything”, each criterion (groundedness, completeness, tone) gets an isolated judge with its own rubric. Mixed scores cannot be diagnosed.
- Structured rubric with thresholds. Explicit levels with markers for each level. A vague rubric produces inconsistent verdicts the same way a vague task produces a noisy pass rate.
- An “Unknown” exit. The judge is explicitly allowed to answer “not enough information”. This reduces hallucinated verdicts on cases outside the rubric.
- Evidence before score. The judge first quotes transcript fragments, then issues the verdict. Order matters: scoring without forced evidence degrades into general impressions.
- Recalibration on schedule. Changing the judge model, its prompt, or product requirements invalidates the previous calibration.
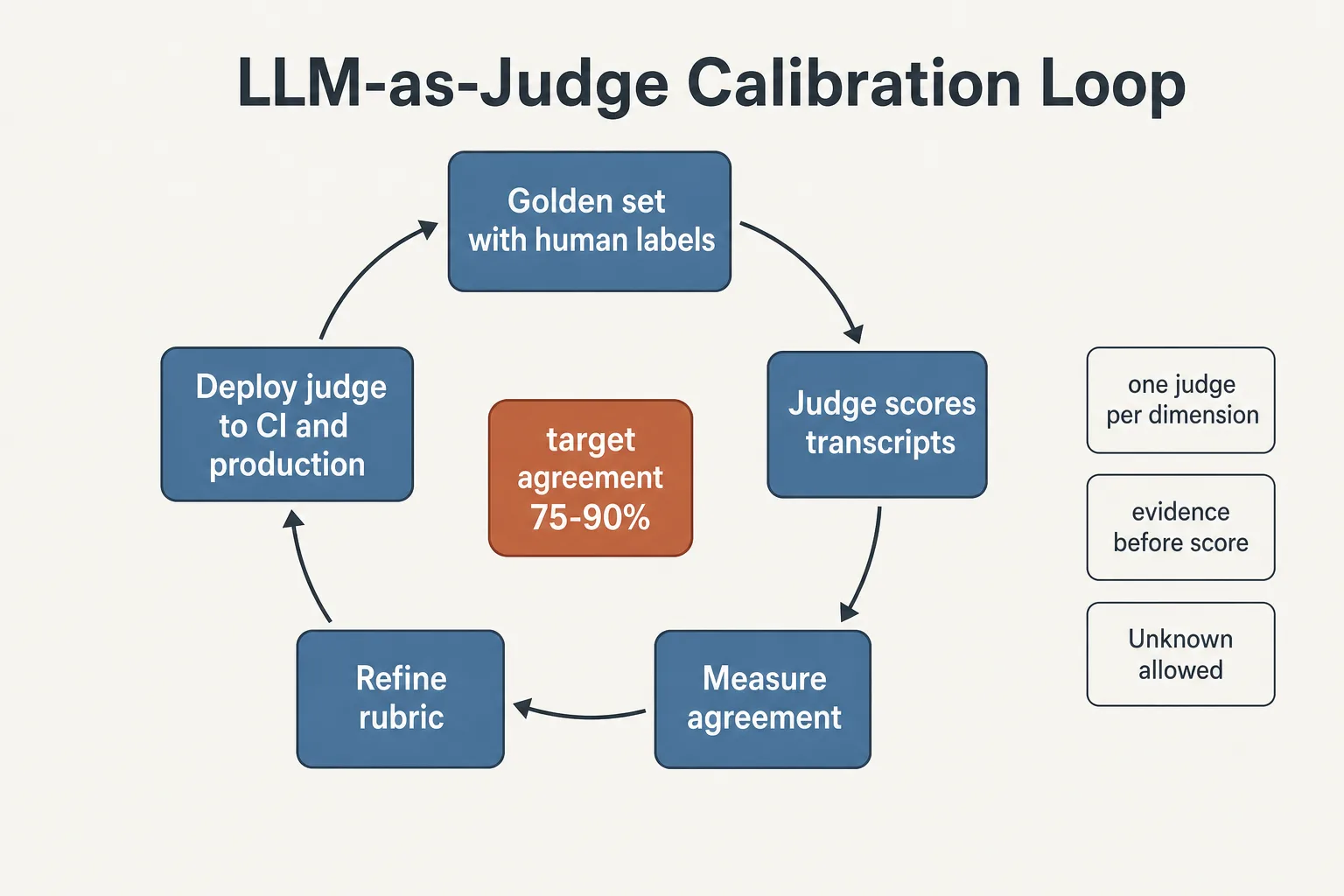
A judge is admitted to release decisions only after measured agreement with experts, and is re-checked on a schedule.
A judge prompt skeleton that implements rules 3-5:
Role: quality evaluator for a support agent's answers.
Dimension: groundedness (this dimension only).
Rubric:
1.0 every factual claim is supported by tool results
present in the transcript
0.5 claims are partially supported, some details unsupported
0.0 key claims are not supported by transcript data
Unknown the transcript lacks information for a verdict
Response format:
evidence: [quotes from the transcript]
score: <1.0 | 0.5 | 0.0 | Unknown>
reason: <one sentence>When measuring agreement, remember class imbalance: if 90% of golden cases carry a pass label, a judge that always answers pass shows 90% agreement. So agreement is computed separately for the pass and fail classes, and the threshold must hold on both.
Model judges also carry documented systematic biases. The best studied is position bias in pairwise comparisons: the verdict changes when candidates are swapped, as confirmed by a systematic study of position bias in LLM-as-a-judge. Related effects include a preference for verbose answers and inflated scores for outputs from the judge’s own model family. Practical countermeasures: score candidates independently against a rubric instead of pairwise, and where pairwise comparison is unavoidable, run both orderings and treat verdict disagreement as a signal of an unreliable case.
A separate discipline: reading transcripts by hand on a regular cadence. When a task fails, the transcript shows whether the agent made a real mistake or a grader rejected a valid solution. Teams that do not read transcripts eventually optimize the system against their own graders’ bugs.
Tasks from production logs: the replenishment loop
A suite that is not replenished goes stale within a quarter. The cheapest source of new tasks is production logs: failed sessions, escalations to humans, repeated contacts about the same problem, and sessions with anomalous trajectory length.
The working replenishment cycle:
- Select candidates by signals: escalation, negative feedback, anomalous step count, budget violation.
- Cluster similar failures to avoid duplicate tasks.
- Turn a cluster into an eval task: input, environment fixtures, success criteria, reference solution.
- Anonymize: fixtures get synthetic data that preserves the structure of the case.
The engineering side of this pipeline was covered in the article on product logs as data for post-training: the loops are nearly identical, only the consumer changes. The same log selection and cleaning pipeline can feed both fine-tuning and the eval suite, which is a strong argument for building it as shared infrastructure.
Artifact: eval task spec and release gate
A minimal task spec that ties graders, metrics, and thresholds together in one file:
task_id: refund_flow_037
owner: support-agent-team
scenario: "Order refund with partial bonus payment"
environment:
fixtures: refund_sandbox_v3
tools: [orders_api, refund_api, customer_api]
clock: "2026-06-09T10:00:00Z"
trials: 5
graders:
- type: code
checks:
- refund_created: true
- refund_amount_matches_policy: true
- no_pii_in_response: true
- tool_args_match_schema: true
- max_tool_calls: 6
- type: judge
rubric: support_answer_quality_v2
dimensions: [groundedness, completeness]
threshold: 0.8
scoring: binary
pass_requirement: "pass^5 >= 0.8"
reference_solution: transcripts/refund_flow_037_reference.jsonA release gate on top of a set of such tasks:
release_id: support_agent_2026_06_09_r1
gates:
capability_suite: "task_success_rate >= 0.85"
regression_suite: "pass rate = 1.0"
reliability: "pass^3 >= 0.7 on critical scenarios"
trajectory: "schema violations = 0, allowlist violations = 0"
judge_calibration: "judge_agreement >= 0.8, verified <= 30 days ago"
economics: "cost_per_success <= baseline * 1.15"
decision_rule: "any red gate blocks the promote"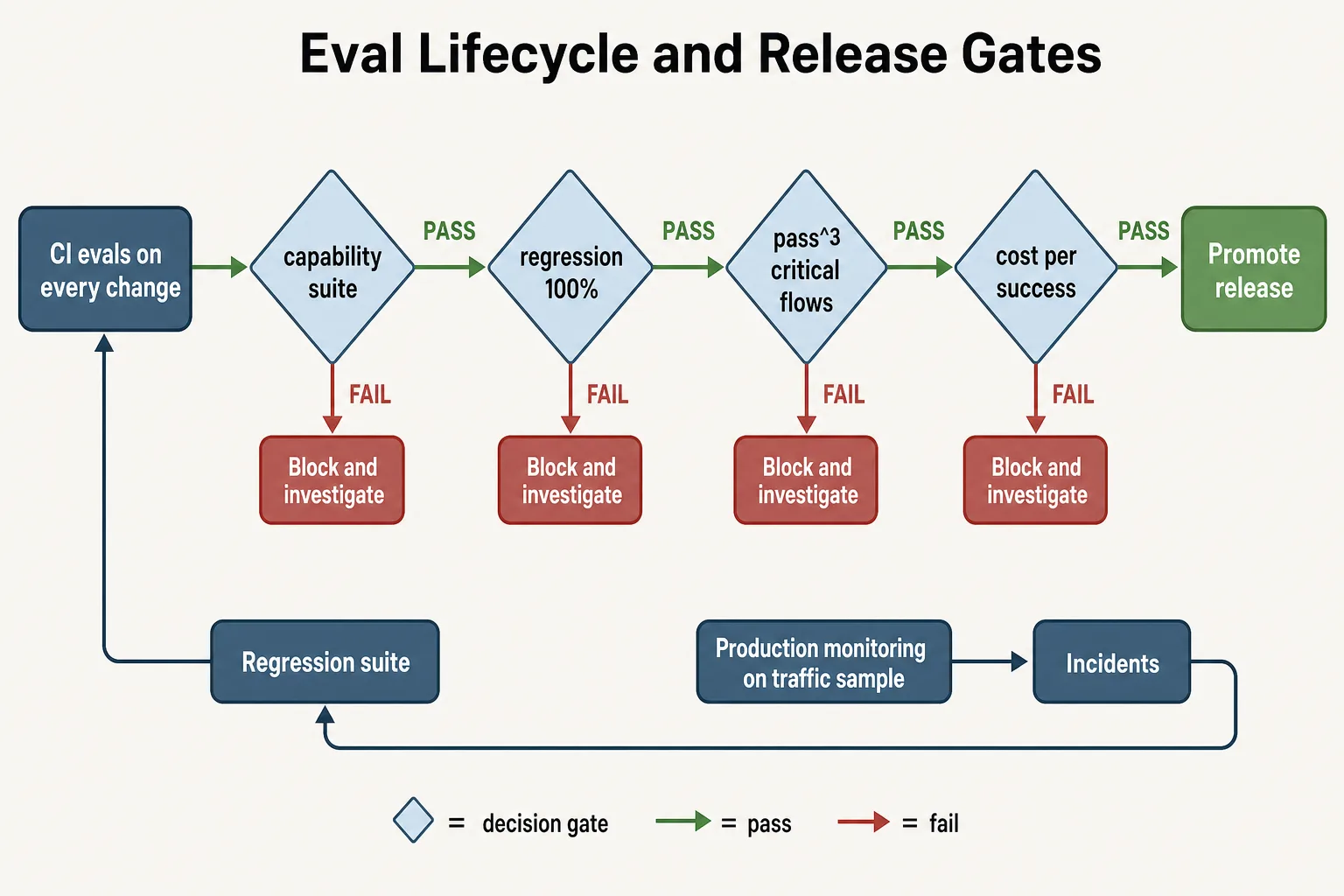
Every gate has a binary decision: a red status blocks the promote, while monitoring and incidents return new tasks into the regression suite.
The gate structure deliberately mirrors the approach from the article on release gates for production ML: the check composition changes, the discipline stays the same. For RAG agents, the gate composition adjusted for security and cost was covered in a dedicated production guide.
Where evals live in the lifecycle
Each evaluation method works at its own stage; they do not substitute for one another.
- On every commit. Smoke suite: 10-15 tasks, 1-3 trials, code-based graders only. Budget: minutes and single-digit dollars. Goal: catch a coarse break before merge.
- Nightly run. Full capability and regression suites, 5-10 trials on critical scenarios, judges enabled. Goal: a daily quality trend and an early drift signal.
- Release. The gates from the previous section. A red gate blocks the promote without debate.
- Production. Asynchronous monitoring on a stratified traffic sample, plus A/B testing for significant changes once traffic is sufficient.
- Continuous background. Triage user feedback, read a sample of transcripts weekly, convert new failures into regression tasks, recalibrate judges on schedule.
This loop structurally matches the one covered for the offline-online gap in RecSys: offline metrics predict online behavior only with logging discipline and regular reconciliation. Agent systems inherit the same problem in a sharper form, because the action space is wider.
Public benchmarks occupy a modest place in this loop. Suites like tau2-bench are useful for comparing base models on typical multi-turn tool-use scenarios: the methodology is published and verifiable. They still do not replace a domain suite, for two methodological reasons. First: the correlation between a generic benchmark and a specific business function is not guaranteed and itself needs verification. Second: public suites leak into training data and into model development targets over time, so a rising public score without a rising domain score is a known pattern rather than an anomaly.
Anti-patterns
- A 100% pass rate as the goal. A suite that is always green has stopped testing the system. A rigorous suite with a 60-80% pass rate is more informative than perfect reports.
- An uncalibrated judge in the gates. Release decisions are made on a metric whose agreement with humans was never measured.
- Outcome metrics only. Trajectory degradations accumulate invisibly: step counts grow, calls become redundant, tool results get ignored.
- Averages instead of pass^k. A mean success rate hides the inconsistency that users experience as a lottery.
- An eval suite without an owner. A suite that is not replenished from incidents goes stale within a quarter and creates a false sense of control.
- Graders that can be gamed. If the agent passes a check without solving the task, the metric measures the quality of the loophole.
- A drifting environment. Unversioned fixtures, live clocks, and shared state between trials turn the eval into a random number generator.
- Different rubrics offline and online. Pre-launch and post-launch numbers stop being comparable, and quality drift gets written off as “traffic specifics”.
Pre-release checklist for gated launches
The rollout order differs per team, but the loop can be verified with one list before release decisions are entrusted to it:
- every task has a reference solution, and it passes all graders;
- two independent expert labelings on a task sample agree;
- model, prompt, tool, fixture, and grader versions are pinned in every run;
- the environment is deterministic: state reset, frozen clock, versioned fixtures;
- the judge is calibrated, with agreement measured separately for pass and fail classes;
- infrastructure retries are separated from failed trials;
- the report can diff two runs at the task level, not just averages;
- gates account for statistical uncertainty, contested cases get extra trials;
- incidents are converted into regression tasks, and the suite has an owner;
- online monitoring uses the same rubrics and thresholds as the offline loop.
The items are deliberately verifiable: each one either holds or it does not. If three or more do not hold, the gates are still measuring noise.
Summary
Agent evals are an architecture layer with the same status as tool contracts and observability. The minimal composition: a capability suite, regression built from incidents, trajectory checks, a calibrated judge, and online monitoring on a shared rubric.
Reliability is measured with pass^k, economics with cost_per_success, and releases are governed by gates with binary decisions. Production is the source of new tasks: incidents, feedback, and transcripts that actually get read.
A system with this loop degrades loudly and gets fixed with data. A system without it degrades silently and gets fixed through complaints.
FAQ
What is the minimal eval set an LLM agent needs before production?
A capability suite for target scenarios, a regression suite built from past incidents, trajectory checks at the tool-call level, a calibrated LLM-as-judge, and online monitoring on a sample of live traffic.
What is the difference between pass@k and pass^k, and when does each apply?
pass@k measures the probability of at least one success in k attempts; pass^k measures the probability of success in all k attempts. For customer-facing agents pass^k matters more: it measures behavioral consistency.
Can you trust LLM-as-judge without human labels?
No. A judge must be calibrated against a golden dataset with human labels, with measured agreement. A working target is 75-90% agreement with experts before running the judge at scale.
How many trials does each eval task need?
1-3 trials per task are enough for CI smoke checks; release decisions on critical scenarios need 5-10. Estimate precision grows with the square root of trial count, so the budget is allocated by criticality.
What does a 100% pass rate on an eval suite mean?
Most often it signals a weak suite that no longer stress-tests the system. A rigorous suite where a strict grader yields 60-80% is more informative because it shows real degradation zones.
Where should eval tasks come from?
Three sources: target scenarios of the business function, production incidents, and clustering of failed sessions from logs. A suite without a constant inflow of production tasks goes stale within a quarter.