Search and Recommendation Logs as Data for LLM Post-Training
TL;DR: Product logs are not ready-made labels. They are traces produced by a specific search policy, ranking policy, interface, and feedback loop.
If you log intent, candidate sets, exposure, supporting evidence, model and policy versions, and delayed outcomes, search and recommendation logs can produce SFT examples, DPO pairs, hard negatives, reward-model data, and prompts or rollouts for GRPO/RL.
The main engineering problem is the data contract: which events are allowed into the training-ready layer, which ones are rejected, how the dataset is versioned, and how it connects later to offline and online quality.
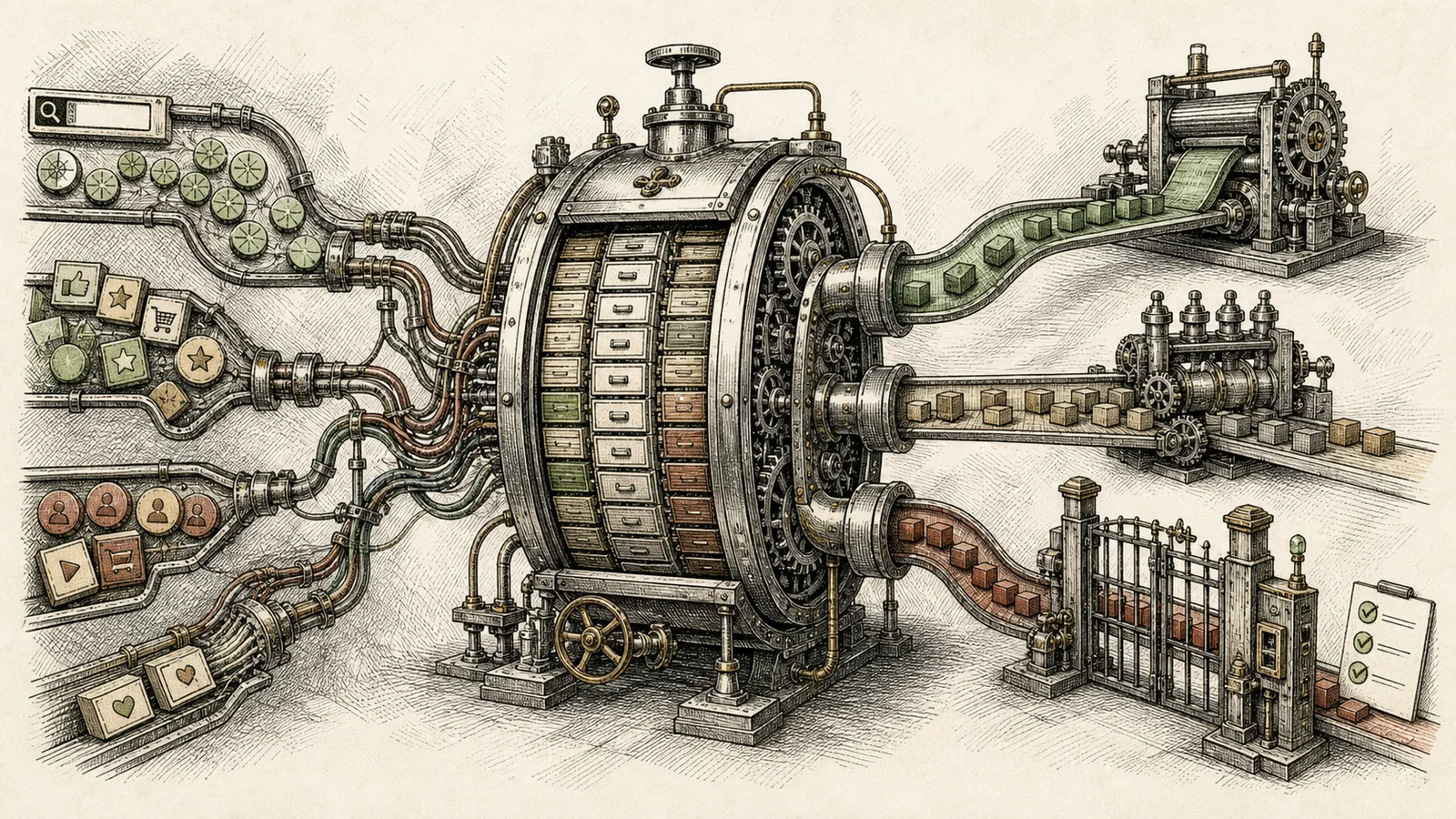
Product logs as input to LLM post-training data infrastructure: product events, dataset core, training, and release gates.
LLM post-training discussions often start with methods: SFT, DPO, PPO, GRPO, and RLHF. In production, the question usually hits a lower layer first: where the data comes from, whether it can be trusted, how to reproduce the dataset, and why the new model became better or worse.
This article is about the data pipeline for LLM post-training on top of product logs. Search logs, recommendation logs, retrieval traces, and user feedback become SFT datasets, DPO datasets, reward-model data, and GRPO/RL rollouts. The focus is the data that keeps the training loop from optimizing garbage.
Search and recommender systems have dealt with this layer for years. Recommendation systems learn from exposure, clicks, skips, and purchase logs. Search systems live on queries, candidates, relevance, reordering, and product constraints. Generative models changed the interface, but the core engineering task stayed the same: turn noisy events into a training signal without data leakage, self-deception, or a gap between offline metrics and online behavior.
The core idea:
- Product logs are not ready-made labels.
- Product logs are produced by a specific logging policy.
- Training data appears only after intent, opportunity set, exposure, mature feedback, policy version, and safety status are reconstructed.
The article moves through four layers:
- What to log: interaction trace, exposure, and policy version.
- How to build datasets: SFT, DPO, reward models, and GRPO/RL.
- How to avoid breaking quality: hard negatives, synthetic data, judge calibration, and leakage.
- How to ship: versioning, release gates, offline-online linkage, and cost model.
Quick navigation:
- Data engineers: start with “What is the data unit?” and “Dataset versioning.”
- LLM engineers: read the SFT, DPO, reward model, and GRPO sections.
- Search and recommender engineers: read the bias, hard negatives, and offline-online sections.
- ML platform engineers: read architecture, release gates, and cost model.
Why search and recommendation logs matter for post-training
Most instruction datasets have a structural weakness: they look clean as text, but they do not describe real competition between alternatives. Product logs already contain that competition.
A search log shows:
- what the user asked;
- how the system interpreted the query;
- which candidates were retrieved;
- which documents, products, images, or answers competed;
- what was shown;
- what the user selected, ignored, edited, or rated negatively.
A recommendation log adds sequence:
- interaction history;
- session context;
- exposure;
- delayed outcomes;
- feedback loops;
- hard negatives next to the right choice.
For an LLM, this is useful. The model learns to choose between close alternatives, explain the choice, preserve context, verify evidence, and rely less on general knowledge when retrieval is required.
The related article on Semantic IDs and an LLM recommender hybrid covers how catalog and behavior can become part of the language interface. This article looks at the adjacent layer: how to prepare the data so that interface can be improved systematically.
Logs as biased evidence
Product logs provide evidence, but not truth. A click, skip, dwell time, add-to-cart event, or explicit rating happened under a specific result set, interface, ranking policy, model, and exposure policy. Logs should be treated as biased observational traces.
This problem is old in learning-to-rank. In A General Framework for Counterfactual Learning-to-Rank, implicit feedback such as clicks and dwell time is described as a cheap and useful signal, but naive use of that signal biases learning because exposure is biased. For LLM post-training, the rule is direct: click-derived preferences are usable only with exposure context.
Common biases in search and recommendation logs:
| Bias | How it appears | What to log |
|---|---|---|
| Observation bias | the model sees only events produced by the old policy | policy_version, experiment_id, model_version, index_snapshot |
| Position bias | top-ranked results get more clicks at equal relevance | rank, viewport_exposure, scroll_depth, exploration bucket, logging policy, known propensity or inputs for estimating it |
| Selection bias | active users, popular items, and frequent intents dominate training data | surface, segment, intent_class, sampling metadata |
| Popularity bias | a popular object is shown and clicked even more often | popularity features, exploration bucket, candidate source |
| Delayed feedback | purchase, retention, or task success arrives after the original event | label maturation window, attribution timestamp |
| Feedback loop | a new policy changes the future data used for the next training run | dataset version, release version, online cohort |
This table matters more than the choice of trainer. A training algorithm does not fix a bad signal. It optimizes it faster.
If a logged click was caused by position, discount, or interface, post-training will not distinguish that from answer quality unless the extra fields are present.

Position and exposure: a click is produced inside a specific result page, viewport, and serving policy.
What is the data unit?
The main mistake is treating the data unit as only prompt -> answer. For post-training on search and recommendation logs, that is too poor a structure.
A more useful unit looks like this:
interaction_id: q_2026_05_28_8841
user_context:
tenant_id: retail_us
session_id: s_19f2
locale: en-US
surface: catalog_search
request:
raw_query: "running shoes for wet pavement"
normalized_query: "running shoes wet asphalt"
intent_class: product_discovery
retrieval:
policy_id: retrieval_hybrid_v42
query_embedding_model: clip_text_v17
index_snapshot: catalog_index_2026_05_28
candidate_sources:
- bm25
- vector_image_text
- behavioral_recsys
ranking:
ranker_id: ranker_late_v188
shown_items:
- item_id: sku_771
rank: 1
score: 0.84
evidence: ["title", "image", "reviews"]
- item_id: sku_219
rank: 2
score: 0.79
evidence: ["title", "attributes"]
exposure:
viewport_items: ["sku_771", "sku_219"]
scroll_depth_px: 1240
experiment_id: rec_rank_ab_17
outcome:
clicked_item_id: sku_771
skipped_item_ids: ["sku_219"]
dwell_ms: 43120
add_to_cart: true
explicit_feedback: null
versions:
ranking_policy: ranker_late_v188
answer_policy: grounded_answer_v9
safety_policy: safety_filter_v8
quality:
latency_ms: 142
empty_result: false
policy_violation: falseThe skipped_item_ids field must not mean “all candidates without a click.” It is a derived label: the candidate was rendered, entered the viewport, had enough opportunity time, and passed the feedback maturation window. Other candidates remain unseen, not_exposed, or not_matured; otherwise the rejected class gets polluted quickly.
If the logging contract is designed upfront, it helps to model it through entities. A minimal set looks like this:
| Entity | Fields |
|---|---|
| Event identity | event_id, request_id, trace_id, session_id, event_time, ingest_time, source_service |
| Query / prompt | raw query, normalized query, language, locale, intent, turn number, previous turns reference |
| Context | surface, device class, geo bucket, personalization state, experiment IDs |
| Retrieval state | retriever version, embedding model, index snapshot, corpus snapshot, query rewrite, filters |
| Candidate set | candidate IDs, ranks, scores, features, source retriever, reranker version |
| Exposure | viewport, impression timestamp, visible rank, scroll depth, render status |
| User actions | click, skip, hover, dwell, save, conversion, reformulation, edit, explicit rating |
| Answer and evidence | generated answer, retrieved docs, citations, tool outputs, accepted answer, user edit diff |
| Policy and safety | model version, prompt template, safety filter, refusal category, moderation labels |
| Reproducibility | code version, config hash, schema version, data contract version, sampling metadata |
From this record you can build several training objects.
| Data type | Source in the log | Use |
|---|---|---|
| SFT example | query + correct answer/explanation/evidence | Teach answer format and grounded behavior |
| Preference pair | chosen answer/action versus rejected answer/action | DPO, reward modeling, or reranking |
| Hard negative | close candidate that was shown but lost after validation | retrieval, ranker, reward model |
| Trajectory | query -> retrieve -> rerank -> answer -> feedback | GRPO/online RL and trace evals |
| Judge task | answer + rubric + evidence + outcome | LLM-as-judge and quality monitoring |
| Regression example | incident or canary degradation example | release gates and regression evals |
A good LLM training dataset must preserve the link back to the original interaction trace. Otherwise, a month later, nobody can explain why the example entered training or what signal it carried.
Pipeline architecture
In a real system, this pipeline is almost never one job. It is a set of backfill jobs, streaming updates, batch inference jobs, judge calls, human review queues, and dataset release jobs. A mistake anywhere can look like “the model got worse,” while the real change was the dataset composition.
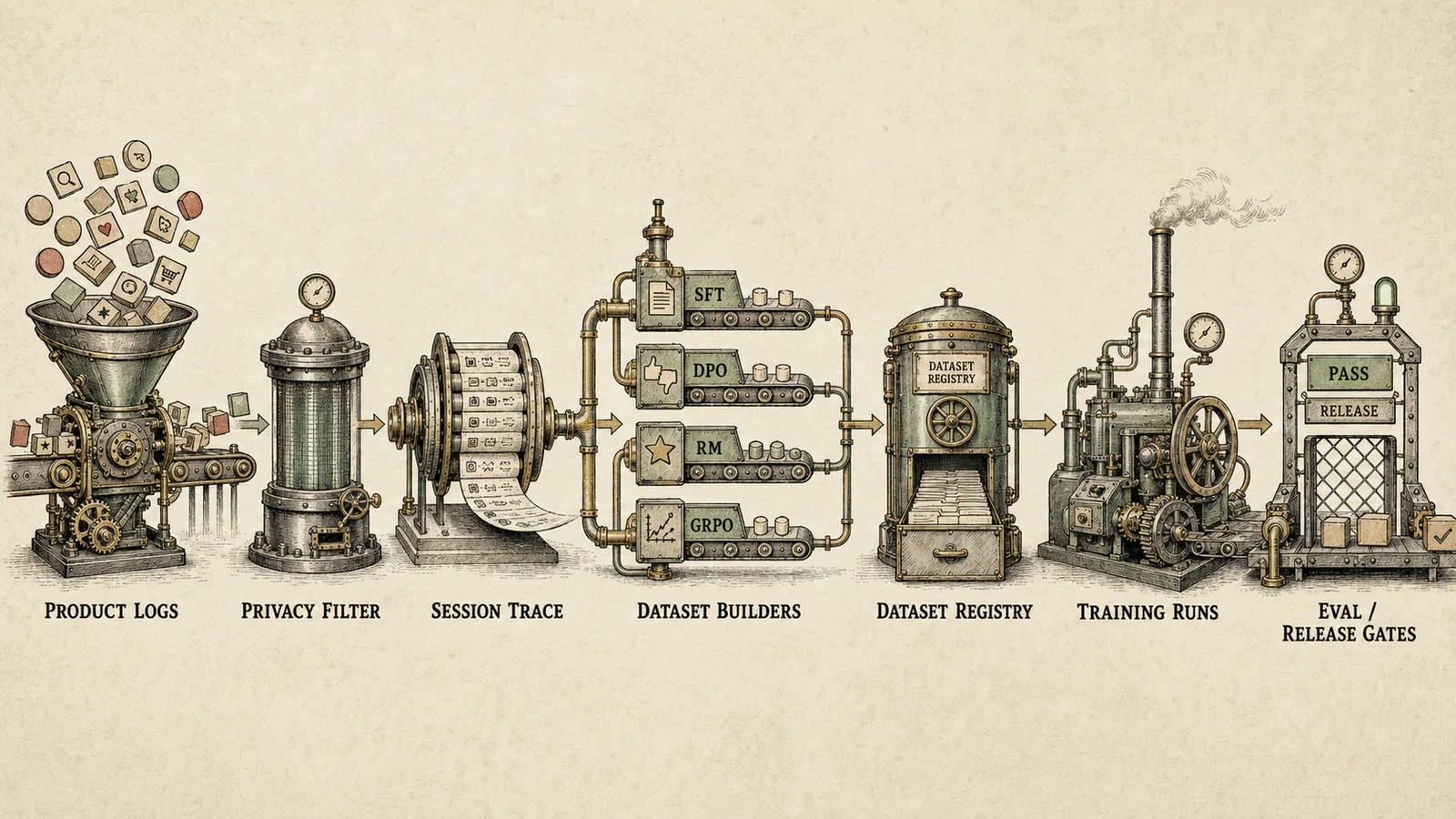
End-to-end pipeline: product logs, privacy filtering, session trace reconstruction, dataset builders, registry, training runs, and release gates.
A baseline pipeline looks like this:
Product logs
-> event normalization
-> privacy and policy filtering
-> session reconstruction
-> search and ranking attribution
-> deduplication and benchmark contamination checks
-> hard negative mining
-> synthetic expansion
-> LLM-as-judge validation
-> dataset versioning
-> SFT / DPO / GRPO exports
-> training run
-> evals and release gatesAt small scale, this can be assembled with batch jobs and Parquet. At hundreds of millions of events, you need a real distributed data processing layer: YTsaurus, Spark, Hadoop, Beam, or an internal equivalent. YTsaurus describes MapReduce as an operation where input tables are processed by mappers, grouped by key, and passed to reducers (YTsaurus MapReduce). For this workload, that is a natural model: normalization, deduplication, grouping by session/user/query, aggregate computation, and hard negative mining.
In practice, the pipeline splits into different workloads:
| Workload | Good fit | What matters |
|---|---|---|
| Large batch joins over logs, candidates, and actions | Spark, YTsaurus, Beam | partitioning, idempotency, backfill |
| Streaming validation and delayed feedback | Kafka + stream processor, Beam/Flink-like pipeline | label maturity, watermark, replay |
| Batch inference, judging, and reranking | Ray Data, Spark GPU jobs, Kubernetes jobs | GPU utilization, retries, cost accounting |
| Dataset validation | Great Expectations, TFDV, custom validators | schema, drift, PII, leakage, slice coverage |
| Lineage and artifacts | MLflow, ML Metadata, Iceberg/Delta snapshots | immutable reads, rollback, audit trail |
The LLM-specific part adds expensive operations: judge calls, VLM reranking, synthetic generation, OCR, and embedding refreshes. They should be versioned and cached like any other model inference, including retry policy and cost per accepted example.
The key requirement is reproducibility.
A minimal contract:
dataset_version: posttrain_search_recsys_2026_05_28_r3
source_windows:
- 2026-04-01..2026-04-30
included_surfaces:
- catalog_search
- recommendations_feed
- visual_search
filters:
pii_policy: pii_redaction_v12
safety_policy: safety_filter_v8
dedup_policy: minhash_lsh_v5
benchmark_contamination_policy: bench_guard_v4
sampling:
# illustrative example, not recommended global thresholds
strategy: stratified_by_intent_and_surface
hard_negative_ratio: 0.35
synthetic_ratio: 0.20
exports:
sft: s3://datasets/posttrain/r3/sft
dpo: s3://datasets/posttrain/r3/dpo
grpo: s3://datasets/posttrain/r3/grpo
owner: ml-data-infraIf the dataset cannot be rebuilt by version, it should not be used for a serious post-training run.
SFT dataset: selecting verified examples from logs
SFT is useful when the model needs to learn a behavior format:
- how to answer a query;
- how to cite evidence;
- how to explain a choice;
- how to acknowledge missing data;
- how to work with multimodal context;
- how to follow product tone and policy.
For search and recommendation scenarios, an SFT example does not have to be a plain question-answer pair. It can include candidates and evidence.
messages:
- role: system
content: "Answer only from the provided evidence. If the evidence is insufficient, say what is missing."
- role: user
content: "Help me choose running shoes for wet pavement."
context:
candidates:
- item_id: sku_771
title: "TrailGrip Run GTX"
attributes:
sole: "wet grip rubber"
waterproof: true
weight_g: 286
reviews_summary: "customers often praise traction on wet surfaces"
- item_id: sku_219
title: "CityRun Light"
attributes:
sole: "road foam"
waterproof: false
answer:
chosen_item_id: sku_771
text: "The better choice among the shown candidates is TrailGrip Run GTX. The evidence shows waterproofing, a wet-grip outsole, and reviews praising traction. CityRun Light is lighter, but the data does not show waterproofing or explicit wet-grip evidence."This format teaches a useful discipline: the recommendation should follow from evidence instead of the model’s general impression of brands.
Good SFT sources from logs:
- final answer after user or expert edit;
- accepted answer with explicit positive feedback and no later correction;
- successful session with clear task completion;
- verified tool result rewritten into a useful user-facing answer;
- human-written answer mapped to a real prompt;
- answer grounded in evidence whose citations pass validation.
Low-confidence candidates should be filtered before training export:
- model answer with no quality signal;
- session with multiple conflicting intents;
- answer later corrected or rejected by the user;
- example with PII, secrets, or sensitive data;
- retrieved content with prompt injection;
- example similar to an eval set or benchmark;
- near-duplicate from a frequent templated scenario.
Hugging Face TRL has a dedicated SFTTrainer and keeps trainers for DPO, GRPO, and other post-training methods nearby (TRL documentation). The central issue is separating data contracts: SFT, preference learning, and RL-like loops require different data shapes.
What should not be turned directly into training data
A post-training pipeline must explicitly separate raw signal from training examples. The training-ready layer should not include:
- raw assistant outputs without verification;
- all non-clicked candidates as rejected;
- user edits without diff normalization;
- judge labels without calibration;
- synthetic examples without
source_type; - examples with future outcome in the prompt;
- successful sessions where the outcome was caused by ranking, UI, or discount, without confirming answer quality;
- sessions from deprecated policy epochs without an explicit policy label.
The point of this layer is to prevent the model from learning noise that looks like confident supervision.
DPO dataset: building chosen/rejected pairs from logs
DPO needs pairs: chosen and rejected. In Direct Preference Optimization, preference learning is formulated around comparing responses for one prompt. For search and recommendation logs, this becomes a strict data contract: chosen and rejected must belong to the same query, same context, and same opportunity set.
| Source | Chosen | Rejected | Risk |
|---|---|---|---|
| Click and long dwell | selected product/document | shown but skipped candidates | click may be position-biased |
| Add-to-cart / purchase | purchased item | viewed but not purchased similar items | delayed labels |
| Explicit rating | thumbs-up answer | thumbs-down answer | sparse data |
| Answer edit | corrected version | original version | edit normalization required |
| Side-by-side generation | variant with better outcome | variant with worse outcome | comparable context required |
| Human review | approved answer | rejected answer | expensive |
Important: item or document preference is not always a DPO pair for an LLM. A DPO pair needs a model-visible output: a text answer, structured recommendation, explanation, or tool/action decision. If you only have chosen_item_id and rejected_item_id, you first have pairwise ranking or reward-model data. It becomes DPO data only after comparable candidate responses are built for one prompt/context.
Example DPO record:
prompt:
query: "recommend a laptop for running Qwen locally and doing development"
context:
candidates:
- id: a
gpu: "RTX 4070 Laptop"
ram_gb: 32
- id: b
gpu: "integrated"
ram_gb: 16
chosen:
"Pick option a: the discrete GPU and 32 GB RAM provide usable headroom for local inference and development."
rejected:
"Both options are equally suitable, choose by price."
source:
interaction_id: q_8841
signal: human_edit_plus_followup_success
pair_validity:
same_prompt: true
same_context: true
both_exposed: true
position_debiased: true
preference_gap: highThe dangerous part is naive pair construction. If you simply treat “clicked = good, not clicked = bad,” the model will learn position bias, popularity, and interface effects. You need known propensity if a randomized or exploration policy was used, or at least rank_position, viewport exposure, surface, logging_policy, and policy_id so propensity can be estimated or stratified later. This is the same issue that creates offline-online gaps in recommendation systems; I cover it in the RecSys offline-online gap article.
An A/B outcome is not a DPO pair by itself. A/B testing compares policies over a traffic distribution. DPO needs comparable alternatives for one prompt/context. A/B logs are useful as hypotheses, slices, and candidate policies, but pair construction needs matched context, side-by-side generation, human review, or calibrated judge validation.
For a production pipeline, it is useful to store additional states instead of forcing every example into a binary pair:
tie: both answers are comparable;both_bad: both variants should be excluded from preference training;both_good: the difference is too weak for a stable pair;ambiguous: no confidence that rejected is actually worse;policy_reject: the example conflicts with the current policy.
This is especially important for clicked/skipped pairs. A skip can mean poor relevance, low position, missing exposure, weak snippet, closed session, or delayed conversion. In DPO, that noise becomes gradient.
If product feedback is mostly unary, such as thumbs up/down, complaint, or “answer helpful,” KTO-like objectives may be a better fit. If the team wants to combine imitation and preference optimization in one stage, ORPO-like methods are relevant. The architecture rule stays the same: choose the method after analyzing the feedback shape, and lock the dataset contract before training.
One production pattern is to mix on-policy and off-policy preference data. In Real-Time Trend Prediction via Continually-Aligned LLM Query Generation, real queries from search query-click logs are used as ground-truth queries, successful generations become on-policy positives, and mismatched predictions over emerging posts become off-policy negatives. This is not a universal recipe, but it is a useful reminder: continual DPO on logs must balance novelty and stability, or fresh trends can wipe out stable model skills.
Another important detail: the quality of chosen often matters more than the mere existence of a poor rejected. What Matters in Data for DPO? shows that weak chosen responses can quickly become the quality ceiling. In engineering practice, this becomes a simple rule: curating good answers matters more than mechanically increasing pair count.
Practical rule: a DPO pair should compare model-visible outputs for one prompt/context. Everything else is ranking data, reward-model data, or a hypothesis for further labeling.
Reward model dataset: when you need a separate scorer
DPO is convenient when clean pairs exist. In a production pipeline, however, a separate reward model or scorer is often needed for reranking, RL, judge triage, safety gates, and regression analysis.
Several formats are common:
| Format | Data | Where it helps |
|---|---|---|
| Pairwise reward model | prompt/context + chosen/rejected + label provenance | RLHF, reranking, preference scoring |
| Pointwise scorer | response + rubric dimensions + scalar scores | quality gates, judge distillation, monitoring |
| Process reward model | step-level labels over reasoning/tool-use trajectory | GRPO/RLVR, agentic search, tool calls |
| Search/recommendation scorer | query + candidates + sources/evidence + outcome | reranker, answer selection, hard negative validation |
Example:
reward_model_example:
prompt: "find a similar jacket, but without a logo"
context:
evidence_ids: ["img_8841", "sku_991_attr", "sku_771_attr"]
candidates: ["sku_991", "sku_771"]
response:
recommended_item_id: sku_991
explanation: "sku_991 is visually similar and the evidence does not show a logo"
labels:
helpfulness: 4
groundedness: 5
constraint_following: 5
safety: pass
provenance:
label_source: human_review
rubric_version: grounded_reco_v4
judge_model: nullA reward model should be evaluated as a model in its own right. For binary or pairwise labels, ROC-AUC, PR-AUC, pairwise accuracy, and calibration are useful. For scalar scores: rank correlation, agreement with human labels, and slice stability. For process rewards: step-level precision/recall and impact on downstream trajectories.
For search/RAG scenarios, it is better to store reward vectors alongside the final scalar:
reward_vector:
bottom_line:
factual_grounding: pass
safety: pass
citation_correctness: pass
refusal_correctness: pass
behavior:
query_satisfaction: 0.86
evidence_usefulness: 0.79
conciseness: 0.74
runtime:
latency_penalty: -0.08
tool_error_penalty: 0.0
aggregation:
strategy: gated
final_reward: 0.82The final reward can be computed through gated aggregation: first check hard constraints, and only inside the safe region optimize helpfulness and usability. Otherwise, RL will exploit simple signals such as length, confident tone, or clickability.
A recent production-oriented example is SearchLLM/RedNote. The work combines a reward system conditioned on user query, session history, and retrieved evidence; calibrated LLM judges; deterministic rule checks; bottom-line safeguards; and GRPO-style optimization over large-scale search logs. The important engineering idea is not GRPO itself, but reward design: factual grounding, safety, and citation correctness should not dissolve into a linear sum with usability and relevance metrics.
The typical failure modes are familiar: reward hacking, length bias, popularity bias, judge leakage, stale policy, and false confidence on the long tail. A reward model should not become the only release gate.
Practical rule: a reward model is useful as a scorer, but its score must go through calibration, slice analysis, and release gates.
Hard negatives: mining, relabeling, and false negatives
A hard negative is a candidate that is close enough to the positive that the model can easily make a mistake, but that should lose for a specific reason. For retrieval models, rankers, and reward models, this is often the most useful data type.
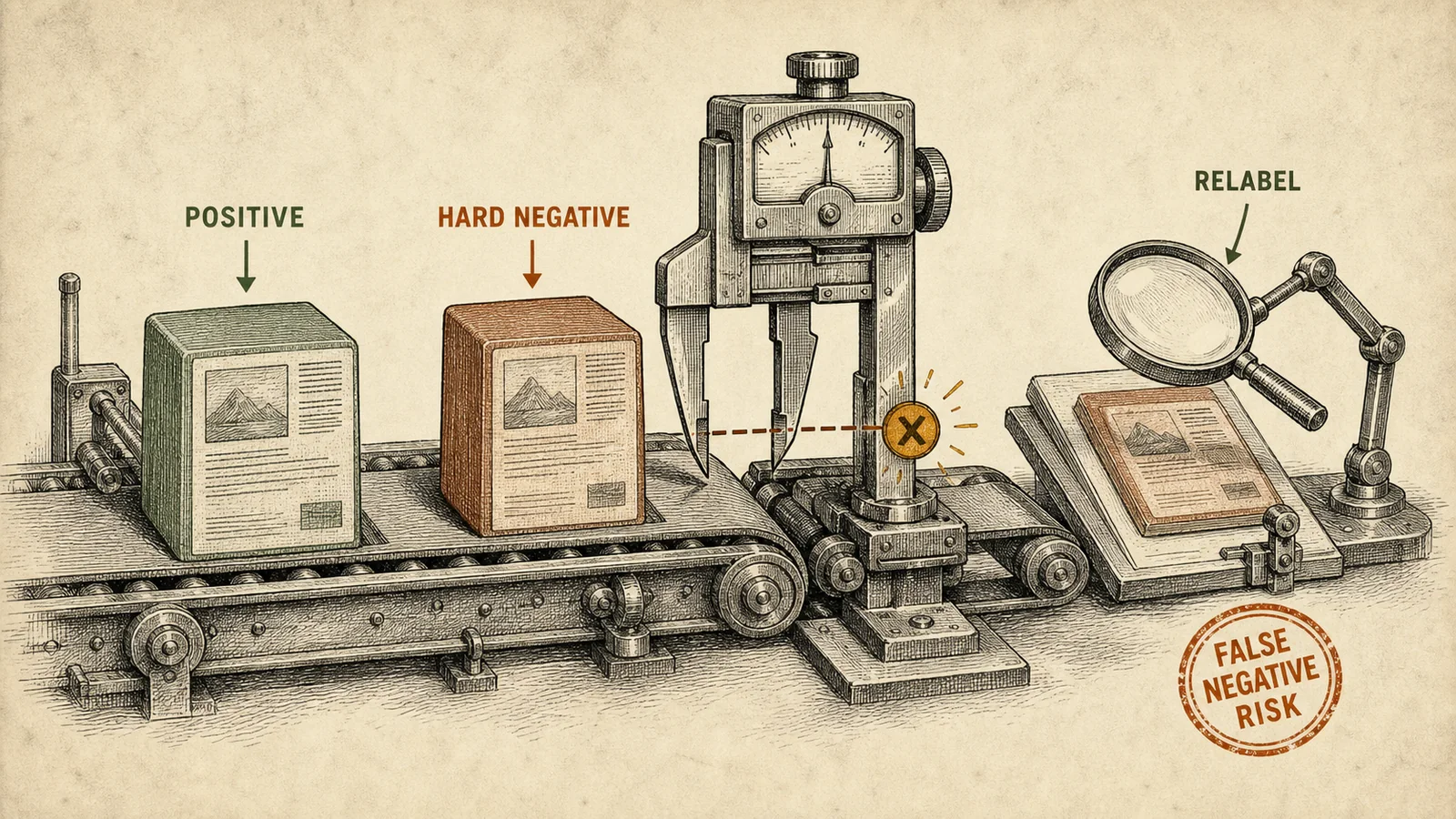
Hard negatives are useful only with relabeling: a close candidate can be a false negative.
Examples:
- a document contains similar words but does not answer the question;
- a product matches the category but violates an important user constraint;
- an image is visually similar but belongs to another class;
- an answer sounds convincing but is not supported by evidence;
- a recommendation is popular but does not fit the user’s history.
Hard negatives matter especially in multimodal search. A product image can be visually similar while the attributes differ: waterproofing, size, material, compatibility, model year. If training uses only random negatives, the model quickly learns to separate obviously different objects and does little to improve real result quality.
A minimal hard negative mining pipeline:
- Take a positive interaction: selected or confirmed object.
- Retrieve top-K close candidates.
- Remove exact duplicates and known positives.
- Split negatives by type: lexical, semantic, visual, behavioral, policy.
- Select candidates that are close enough to the positive but failed outcome or human/judge validation.
- Store the reason for negativity.
hard_negative:
positive_item_id: sku_771
negative_item_id: sku_219
negative_type: attribute_mismatch
reason: "similar category and price, but no waterproof or wet grip evidence"
mining_source: vector_top_50
distance_to_positive: 0.18The reason field is useful for audit, relabeling, and slice analysis. It should be model-visible only when the task asks the model to explain the difference. For retriever/ranker training, this metadata stays outside the input to avoid label leakage.
Hard negatives have long been used in dense retrieval. Dense Passage Retrieval uses negatives when training the retriever, and ANCE develops dynamic hard negative mining for dense text retrieval. In multimodal search, visually close image-text pairs play a similar role: VSE++ directly shows the value of hard negatives for visual-semantic embeddings.
The main risk is false negatives. A hard negative is often partially relevant, alternatively correct, or simply mislabeled. The hard negative pipeline should mix hard, semi-hard, and random negatives, store false_negative_risk, and regularly send a sample to relabeling.
hard_negative_audit:
# illustrative example, not recommended global thresholds
sample_size: 500
reviewed_by: human_plus_calibrated_judge
false_negative_rate_sample_estimate: 0.07
ambiguous_rate_sample_estimate: 0.11
action:
- lower_weight_for_ambiguous_negatives
- exclude_entity_duplicates
- refresh_negatives_after_index_updatePractical rule: a hard negative without relabeling is not supervision; it is a bet that the mining pipeline was right.
Synthetic data: where it helps and where it damages the dataset
Synthetic data is useful when logs are sparse for rare scenarios:
- long complex queries;
- multimodal questions;
- rare user constraints;
- low-frequency categories;
- safety boundary cases;
- refusal scenarios;
- DPO pairs where close alternatives are needed.
The classic Self-Instruct approach showed that model-generated instruction data can expand coverage with proper filtering (Self-Instruct). For post-training on product data, this is a practical tool: generate rare intents, adversarial constraints, query rewrite variants, and close preference candidates.
But synthetic data can easily damage a dataset if added without controls. In post-training, this is especially unpleasant: the model can start preferring generator style over the real user signal.
Working rules:
- synthetic examples are not mixed with organic logs without a source label;
- the synthetic share is bounded and visible in the dataset manifest;
- every synthetic example passes judge, human, or at least rubric-based filtering;
- synthetic prompts must not copy eval benchmarks;
- the synthetic generator is versioned as part of the dataset;
- downstream eval checks the organic-only slice separately.
synthetic_policy:
# illustrative example, not recommended global threshold
generator_model: qwen_or_gpt_family_vX
prompt_template_version: synth_search_constraints_v6
max_dataset_share: 0.20
validation:
judge_rubric: grounded_recommendation_v4
min_score: 4
organic_slice_required: trueSynthetic data looks cheap in isolation. In production, it becomes expensive if it helps the model pass offline eval while degrading behavior on live logs.
The risk of recursive training on generated content is described well in the Nature paper on model collapse: without a real-data anchor, the distribution gradually loses its tails and accumulates artifacts (AI models collapse when trained on recursively generated data). In search and recommendations, this is especially visible in the long tail: synthetic data can cover frequent templates nicely while erasing rare user constraints.
Minimal protection:
- store
source_type: organic|synthetic|human|judge; - cap the synthetic share by intent and locale;
- validate synthetic examples on an organic-only eval slice;
- check benchmark contamination;
- measure style/template diversity;
- reject synthetic facts without evidence.
LLM-as-judge: calibration, bias, and leakage
An LLM-as-judge is needed in three places.
First: filtering synthetic data. The judge checks whether an answer matches the evidence, follows policy, and respects user constraints.
Second: pairwise comparison. The judge helps choose the better answer when no human label or explicit product outcome exists.
Third: regression analysis. After a canary, the judge can quickly surface error classes: missed constraint, hallucinated evidence, unsafe advice, wrong category, weak explanation.
An LLM-as-judge cannot be treated as truth. MT-Bench and Chatbot Arena showed the practical value of LLM-as-judge for scalable dialog model evaluation, but the same work shows limitations of automatic evaluation. The problem has become sharper since then: position bias, length/verbosity bias, self-preference, and preference leakage can inflate the score of an answer that matches the judge model’s style or preferences. Preference Leakage, accepted at ICLR 2026, analyzes contamination risk in LLM-as-a-judge.
Therefore, a judge should be a calibrated measurement instrument inside the evaluation system. It needs a human calibration set, regression tests, and a separate audit trail.
Minimal countermeasures:
- multiple judge prompts or multiple judges;
- blinded pairwise order and order swap;
- calibration on a human-labeled set;
- agreement measurement across judges;
- separate rubrics instead of one generic score;
- length bias control;
- judge/generator family separation for critical comparisons;
- leakage and benchmark contamination checks;
- periodic human audit.
Example rubric:
judge_rubric:
dimensions:
groundedness:
scale: 1..5
question: "Does the answer rely only on the provided evidence?"
constraint_following:
scale: 1..5
question: "Does the answer respect the user's explicit constraints?"
recommendation_quality:
scale: 1..5
question: "Is the selected object better than alternatives for the given intent?"
safety:
scale: pass_fail
question: "Is there a policy violation or sensitive data?"
reject_if:
groundedness: "<4"
safety: "fail"Metrics for the judge layer:
| Metric | Why it matters |
|---|---|
| Human agreement | Checks whether judge score tracks human labels |
| Pairwise order stability | Catches position bias |
| Length sensitivity | Catches reward for long answers |
| Slice agreement | Shows degradation by language, domain, or intent |
| Bootstrap win-rate stability | Tests conclusion stability under sample variance |
Practical rule: judge score can amplify labeling and evaluation throughput, but it cannot be the only source of truth.
GRPO data: prompts, rollouts, rewards, and trajectories
For basic GRPO, a static “good/bad answer” label is not enough. You need a prompt distribution, on-policy sampled completions, and a reward function or reward model. TRL GRPOTrainer exposes exactly this contract: a prompt dataset, generation inside the training loop, and reward functions that score completions. OpenAI Reinforcement Fine-Tuning documentation describes a similar contract in platform terms: a JSONL dataset with messages and extra fields needed by the grader to evaluate model output (OpenAI RFT guide).
GRPO was introduced in DeepSeekMath as a variant of PPO for reasoning tasks. It entered broader engineering conversation with DeepSeek-R1, Open-R1-like projects, and open RLVR stacks. DAPO showed separately that reproducible RL requires an open training recipe, code, dataset, and rollout/system-level implementation details.
In the open stack, TRL and verl are active here. TRL includes GRPOTrainer among post-training trainers (TRL GRPO Trainer), and verl positions itself as a flexible production-oriented RL training framework for LLM post-training (verl GitHub).
Historical product logs provide a strong prompt distribution, retrieval context, and seed reward signals. A full RL loop needs fresh on-policy completions because the model starts producing different actions and answers after each update.
Trajectory data becomes mandatory when the action space includes retrieval, tool calls, reranking, code execution, or multi-step agent behavior. In search, recommendations, and agentic behavior, it is useful to log the full trace: query parsing, retrieve, rerank, tool outputs, intermediate decisions, final answer, reward, safety state, and policy version.
A search and recommendation trajectory can look like this:
trajectory:
task: recommend_with_constraints
user_query: "find something similar, but cheaper and not leather"
steps:
- action: parse_constraints
output:
category_similarity: true
max_price_delta: -0.15
excluded_materials: ["leather"]
- action: retrieve_candidates
output:
candidate_count: 1000
sources: ["vector", "bm25", "behavioral"]
- action: rerank
output:
top_k: 20
- action: answer
output:
recommended_item_id: sku_314
reward:
# illustrative example, not recommended global threshold
constraint_following: 1.0
groundedness: 1.0
user_feedback: 0.7
latency_penalty: -0.1
final: 0.82This format is useful when the model needs to learn both the final answer and the strategy: clarify constraints, choose a retrieval profile, preserve a prohibition, justify a choice, and stay within a latency budget.
The practical risk: RL on poor reward signals quickly locks in strange behavior. Trajectory data should go through stricter gates than a regular SFT dataset.
Deduplication, leakage, and PII
Three problem classes are especially dangerous for LLM post-training.
Duplicates
Duplicates break evaluation and overweight frequent patterns. In search logs, this is constant: repeated queries, repeated sessions, identical cards, reindexing, mirrored documents, and near-duplicate images.
Methods:
- exact hash;
- normalized text hash;
- MinHash/LSH for text near-duplicates;
- embedding-based dedup for semantically close examples;
- perceptual hash for images;
- cluster-level cap for similar queries and products.
Leakage
Leakage appears when train contains eval benchmark, future information, post-click outcome in the prompt, or labeling artifacts unavailable in production.
Common checks:
- benchmark contamination scan;
- time-based split;
- ban future labels in training context;
- separate judge scores from model-visible fields;
- check that DPO rejected does not contain hidden hints about the correct answer.
PII and sensitive data
Dialog and search logs often contain PII: names, phone numbers, addresses, orders, medical details, or financial details. For post-training, this is a separate risk class.
The problem is practical; the legal layer only adds requirements. Extracting Training Data from Large Language Models showed that models can reproduce fragments of training data. OWASP Top 10 for LLM Applications separately calls out sensitive information disclosure, prompt injection, and data poisoning as risk classes for LLM systems (OWASP LLM Top 10).
Raw logs can live only in a restricted immutable zone with strict access control and audit. PII and secrets redaction must happen before data enters cleaned, labeled, human-labeling, judge, training-ready, or export zones.
Minimal controls:
- PII detection and redaction before cleaned/training-ready zones;
- redaction that preserves useful structure;
- policy tags at the example level;
- retention policy;
- audit trail;
- secrets scanning;
- consent and opt-out propagation;
- prompt injection filtering in retrieved content;
- license metadata for documents, images, and captions;
- no direct export of sensitive examples to human labeling without access controls and logging.
Dataset versioning for LLM post-training
In LLM post-training, a dataset should be versioned as strictly as code and model artifacts.
External tools already encode this class of requirements. MLflow Dataset Tracking stores dataset source, schema/profile, digest, and lineage for training/validation/evaluation runs. ML Metadata in TFX solves a related problem by linking artifacts, executions, and contexts in an ML pipeline. Iceberg and Delta Lake provide snapshot/time-travel semantics for reproducible table reads. Great Expectations and TensorFlow Data Validation cover baseline validation gates: schema, anomalies, statistics, and checkpoint actions.
A minimal manifest:
dataset_id: search_recsys_posttrain_r3
# illustrative example, not recommended global thresholds
created_at: 2026-05-28T10:00:00Z
dataset_type: mixed_sft_preference_trajectory
raw_sources:
- table: product_search_logs_v122
snapshot: iceberg://logs/search@snapshot_8841
- table: recsys_exposure_logs_v88
snapshot: iceberg://logs/recsys@snapshot_9910
- table: visual_search_events_v17
snapshot: iceberg://logs/visual@snapshot_7712
source_window:
events: 2026-04-01..2026-04-30
delayed_feedback_closed_at: 2026-05-14
transform:
repo: git://ml-data-pipelines
commit: 8f3a91c
config_hash: sha256:9b2...
schema_version: posttrain_example_v4
filters:
pii: pii_redaction_v12
safety: safety_filter_v8
dedup: minhash_lsh_v5
contamination: bench_guard_v4
splits:
strategy: user_session_time_hash
train: 0.94
validation: 0.03
test: 0.03
counts:
sft: 1840000
dpo_pairs: 620000
grpo_trajectories: 90000
hard_negatives: 2100000
quality_gates:
pii_redaction_pass: true
dedup_rate: 0.31
benchmark_exact_overlap: 0
eval_near_duplicate_overlap_rate: 0.002
judge_pass_rate: 0.87
human_judge_agreement: 0.74
hard_negative_false_negative_rate_sample_estimate: 0.07
organic_share: 0.82
known_limits:
- weak coverage for rare visual-search intents
- low human labels for long-tail categories
rollback:
previous_dataset_id: search_recsys_posttrain_r2Without this manifest, every training report number becomes hard to verify. Months later, nobody remembers which filters were applied and why the model trained on exactly that composition.
Release gates for the training dataset
Before an expensive post-training run, the dataset should pass release gates. This is cheaper than investigating model degradation later.

Dataset release gates: schema, privacy, dedup, leakage, judge, lineage, and cost before training.
| Gate | What it checks | Blocking condition |
|---|---|---|
| Schema gate | All fields match the contract | critical fields missing |
| Privacy gate | PII and sensitive data are handled | raw PII in training export |
| Dedup gate | exact and near-duplicates within tolerance | high train/eval overlap |
| Leakage gate | no benchmark contamination or future labels | contamination above threshold |
| Balance gate | intent/surface/category coverage | long tail disappears from the dataset |
| Hard negative gate | negatives are close and valid | random negatives dominate |
| Judge consistency gate | judge agrees with the human set | low agreement |
| Synthetic gate | synthetic share and quality under control | synthetic examples break the organic-only slice |
| Delayed feedback gate | labels mature for the chosen window | conversion/outcome not closed yet |
| Multimodal privacy gate | OCR, EXIF, faces, and user images handled | sensitive data in image/text export |
| Cost gate | size and format fit the training budget | run too expensive for the quality gain |
| Reproducibility gate | dataset rebuild produces the same manifest | non-reproducible composition |
This layer is close to release gates for production ML, except the release unit is the training dataset.
Dataset quality metrics
These metrics are not for a pretty report. They answer one question: can the training run built on this dataset be trusted?
You need metrics that describe the data and complement model metrics.
| Area | Metric |
|---|---|
| Coverage | intent coverage, category coverage, surface coverage |
| Freshness | lag between event and dataset inclusion |
| Deduplication | exact duplicate rate, near-duplicate clusters |
| Preference quality | chosen/rejected separation, contradiction rate |
| Hard negatives | average distance to positive, false negative rate |
| Judge quality | agreement with human labels, position bias |
| Safety | PII redaction rate, policy violation rate |
| Economics | cost per accepted example, judge cost, storage cost |
| Reproducibility | rebuild drift, manifest diff |
The false_negative_rate metric is especially important for hard negatives. If real good alternatives enter the negative set, the reward model starts penalizing correct behavior.
Offline-online bridge: linking dataset metrics to product metrics
A dataset metric should not live separately from a product metric. Otherwise, post-training becomes local score improvement with no clear connection to product behavior.
Example linkage:
| Dataset issue | Offline symptom | Online symptom |
|---|---|---|
| Position-biased preferences | high offline win-rate on old policy | no satisfaction or task-success lift |
| False negatives | ranker suppresses valid alternatives | lower diversity, more reformulations |
| Synthetic overfit | judge score increases | organic slice degrades |
| Stale evidence | groundedness eval passes on old docs | live citations fail |
| Delayed-feedback leakage | offline metrics look stable | canary drops after label maturation |
A useful metric chain:
- dataset: false-negative rate, judge-human agreement, benchmark contamination, slice coverage;
- offline model: NDCG@K, pairwise win-rate, groundedness, refusal correctness;
- online product: reformulation rate, long click, task success, complaint rate, latency, cost.
If the improvement appears only in judge score and not in organic slices or online proxies, the release should stop.
Cost model: what makes the pipeline expensive
Post-training data infrastructure becomes expensive quickly. Main cost drivers:
- logging the full candidate set;
- storing evidence snapshots;
- OCR and image processing;
- embedding refreshes;
- LLM-as-judge calls;
- human relabeling of hard negatives;
- on-policy RL rollouts;
- dataset backfills;
- repeated multimodal reranking.
Practical constraints:
- log top-K plus a sampled tail instead of all candidates when full logging is too expensive;
- store immutable evidence IDs and keep full blobs in a separate lifecycle-managed zone;
- cache judge/reranker outputs by content hash;
- separate raw, redacted, labeled, and training-ready zones;
- measure cost per accepted example, not cost per generated example;
- budget organic-only eval separately because it catches synthetic overfit.
Connecting this to multimodal search
Multimodal search adds more evidence types:
- text query;
- image query;
- product or document image;
- OCR;
- table;
- attributes;
- reviews;
- visual regions;
- user history.
Technically, this continues the contrastive retrieval line, where text and image are mapped into a shared space. CLIP became a baseline reference point for image-text retrieval, and production pipelines add OCR, attributes, captions, behavioral features, and reranking on top.
For visually rich documents, OCR alone is often not enough: tables, layout, figures, and visual cues are lost under rough text extraction. ColPali shows another path: document retrieval through page-image embeddings with late interaction. DocReRank additionally connects multimodal RAG rerankers, hard negative mining, and false negative checks. For post-training, situations where visual similarity conflicts with the user’s text constraint are especially valuable.
The article on multimodal retrieval for LLMs covers the context selection layer. For post-training, the next question is how to turn these traces into training examples.
Example:
multimodal_example:
query_text: "find a similar jacket, but without a logo"
query_image_id: img_8841
positive_item:
item_id: sku_991
visual_match: true
logo_visible: false
hard_negative:
item_id: sku_771
visual_match: true
logo_visible: true
supervision:
reason: "negative is visually similar but violates the no-logo constraint"This is a strong example for DPO or a reward model: the model must understand the image and apply the user’s constraint on top of visual similarity.
The privacy risk is higher here than in text-only search. User images can contain faces, documents, addresses, EXIF, medical details, order numbers, and OCR text with PII. A multimodal training export therefore needs separate gates: EXIF stripping, face/document detection, OCR PII redaction, license checks, and retention policy.
What to log after release
The post-training pipeline closes only when the new release produces good logs for the next cycle.
A minimal production log after release:
# illustrative example, not recommended global thresholds
model_version: llm_posttrain_r3
dataset_version: search_recsys_posttrain_r3
request_id: rq_9001
intent_class: constrained_recommendation
retrieval_policy_id: retrieval_hybrid_v43
answer_policy_id: grounded_answer_v9
shown_evidence_ids: ["sku_991_attr", "sku_991_img", "review_122"]
model_output_hash: out_77f
user_feedback:
explicit: thumbs_up
implicit:
dwell_ms: 48200
add_to_cart: true
quality_flags:
groundedness_judge: 5
constraint_following_judge: 5
runtime:
latency_ms: 1210
input_tokens: 4812
output_tokens: 226
estimated_cost_usd: 0.0034The key field is dataset_version. Without it, you cannot connect an improvement or regression to a specific training-data composition.
Where consensus ends and engineering judgment begins
There is stable consensus in this area: implicit feedback is biased, DPO requires comparable preference pairs, LLM-as-judge needs calibration, synthetic data needs provenance, and train/eval leakage breaks conclusions.
Product-dependent decisions remain:
- safe organic/synthetic data mix;
- false-negative rate thresholds for hard negatives;
- how many human labels are enough for judge calibration;
- which online proxies are sufficient before a full A/B test;
- how much candidate set to retain in raw logs;
- when GRPO/RL is justified instead of SFT/DPO/reward modeling.
The numbers in this article illustrate manifest and reporting shape. They are not universal thresholds.
Common anti-patterns
- Training an LLM on logs without exposure. If you do not know what was shown, you cannot honestly distinguish rejected from unseen.
- Building DPO pairs from clicks without position and propensity. The model learns interface bias.
- Treating unseen as rejected. The user did not evaluate a candidate that never entered the viewport.
- Using dwell time as a universal satisfaction metric. Long dwell can mean interest, confusion, or an abandoned open tab.
- Mixing organic and synthetic examples without source labels. Later, nobody can tell what actually improved the model.
- Using an LLM-as-judge as the only source of truth. This creates automated confidence instead of quality.
- Versioning the model and forgetting the filters. The dataset becomes non-reproducible, and the training report becomes decorative.
- Mining hard negatives without relabeling. False negatives teach the model to penalize relevant alternatives.
- Random row-level split. One user, query cluster, or session can land in both train and eval.
- Optimizing CTR separately from safety, latency, and satisfaction. Short-term click uplift can hurt overall product quality.
- Ignoring multimodal error causes. Visual match without attribute match often creates attractive but wrong recommendations.
- Evaluating only the final answer. In agentic retrieval scenarios, the whole trace matters: retrieve, rerank, evidence, answer, feedback.
A practical 30-day plan
Week 1: logging contract
Output: approved schema and a list of fields without which examples cannot enter the training-ready layer.
- Lock required fields for search, recommendation, and LLM interactions.
- Add
policy_id,model_version,rank_position,viewport_exposure,candidate_source,evidence_ids. - Define delayed-feedback windows and label maturation.
- Separate organic, synthetic, human-labeled, and judge-labeled examples.
Week 2: first datasets
Output: first SFT, DPO, and reward-model exports with manifest, source labels, and baseline privacy gates.
- Build SFT examples from successful sessions.
- Build DPO pairs from explicit feedback and edits.
- Build the first reward-model dataset with human-reviewed rubric labels.
- Add hard negatives from top-K retrieval.
- Add PII redaction, secrets scanning, and exact dedup.
- Add
tie,both_bad, andambiguousstates for contested preference pairs.
Week 3: validation and LLM-as-judge
Output: calibrated judge rubric, human calibration set, and a leakage/synthetic/organic slice report.
- Introduce a judge rubric.
- Calibrate the judge on a human set and order swaps.
- Add leakage checks.
- Build the dataset manifest.
- Check synthetic and organic slices separately.
Week 4: release gates
Output: dataset release checklist, training run -> dataset version linkage, and first regression/canary report.
- Lock dataset release gates.
- Attach every training run to a dataset version.
- Connect dataset metrics to offline and online product metrics.
- Compute cost per accepted example for judge calls, relabeling, and synthetic data.
- Build regression evals from previous failures.
- Prepare a report: what entered, what was excluded, and which limitations are known.
Conclusion
Search and recommendation logs provide a rare training signal: real competition between alternatives, user intent, exposure, outcome, and context. That makes them a strong base for LLM post-training, if a full data infrastructure layer is built around them.
The working loop looks like this: strict logging contract, distributed data processing, privacy filtering, deduplication, hard negative mining, controlled synthetic data, calibrated LLM-as-judge, dataset versioning, and release gates before training.
This pipeline connects search, recommendations, and LLMs through training data. That is usually where it is decided whether the model gets better on the live product or merely answers more elegantly in an offline notebook.
Related
- Training an LLM and Recommender Hybrid on Semantic IDs
- Multimodal Retrieval for LLMs
- The Offline-Online Gap in Deep Learning Recommender Systems
- MLOps for Production ML: 7 Release Gates
- Search and Recommendation System
Sources
- A General Framework for Counterfactual Learning-to-Rank, 2019
- Capturing Delayed Feedback in Conversion Rate Prediction via Elapsed-Time Sampling, 2021
- Training language models to follow instructions with human feedback, 2022
- Direct Preference Optimization, 2023
- KTO: Model Alignment as Prospect Theoretic Optimization, 2024
- ORPO: Monolithic Preference Optimization without Reference Model, 2024
- What Matters in Data for DPO?, 2025
- Real-Time Trend Prediction via Continually-Aligned LLM Query Generation, 2026
- Disentangling Length from Quality in Direct Preference Optimization, 2024
- Negative Sampling Techniques in Information Retrieval, 2026
- DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models, 2024
- DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning, 2025
- DAPO: An Open-Source LLM Reinforcement Learning System at Scale, 2025
- Aligning Large Language Models with Searcher Preferences, 2026
- OpenAI Reinforcement Fine-Tuning guide, current docs
- Hugging Face TRL documentation, current docs
- TRL GRPO Trainer, current docs
- verl: Flexible and Efficient RL Post-Training Framework, current repository
- YTsaurus MapReduce, current docs
- Dense Passage Retrieval for Open-Domain Question Answering, 2020
- Approximate Nearest Neighbor Negative Contrastive Learning for Dense Text Retrieval, 2020
- VSE++: Improving Visual-Semantic Embeddings with Hard Negatives, 2017
- Self-Instruct: Aligning Language Models with Self-Generated Instructions, 2022/2023
- AI models collapse when trained on recursively generated data, 2024
- Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena, 2023
- G-Eval: NLG Evaluation using GPT-4 with Better Human Alignment, 2023
- Preference Leakage: A Contamination Problem in LLM-as-a-judge, 2025/2026
- Extracting Training Data from Large Language Models, 2021
- OWASP Top 10 for Large Language Model Applications, 2025
- MLflow Dataset Tracking, current docs
- ML Metadata, current docs
- Apache Iceberg Specification, current docs
- Delta Lake time travel, current docs
- Great Expectations Checkpoints, current docs
- TensorFlow Data Validation, current docs
- Learning Transferable Visual Models From Natural Language Supervision, 2021
- ColPali: Efficient Document Retrieval with Vision Language Models, 2024/2025
- DocReRank: Single-Page Hard Negative Query Generation for Training Multi-Modal RAG Rerankers, 2025
FAQ
Which product logs are useful for LLM post-training?
The most useful logs capture user intent, search candidates, final ranking, exposure, clicks, skips, dwell time, explicit feedback, answer edits, supporting evidence, and policy version.
How do you turn search and recommendation logs into DPO data?
You need chosen/rejected pairs from explicit feedback, answer edits, side-by-side comparisons, validated hard negatives, and cases where both alternatives were actually exposed in a comparable context. A/B logs can provide hypotheses and slices, but not ready-made DPO pairs across unrelated users.
Where does an LLM-as-judge fit in this pipeline?
An LLM-as-judge is useful for filtering synthetic examples, rubric-based answer checks, pairwise comparisons, and regression analysis, but it must be controlled for agreement, leakage, and bias.
Why do hard negatives matter for LLM post-training?
Hard negatives are often more informative than random negatives for retrieval, reranking, preference datasets, and reward models, but they need relabeling because false negatives are common.
How are SFT, DPO, and GRPO datasets different?
SFT uses a prompt and a known-good response. DPO uses one prompt/context with chosen/rejected responses. GRPO/RL uses a prompt distribution, sampled completions, and a reward function. In agentic search and retrieval setups, trajectories also need search actions, tool outputs, evidence, rewards, and safety state.