MLOps for Production ML: 7 Release Gates for Controlled Rollouts
TL;DR: Production ML breaks at the transition from “valid in a notebook” to “stable in a service.” A working MLOps loop is not one dashboard. It is a strict set of release gates: data, quality, robustness, performance, cost, observability, and rollback. If any gate fails, the release does not go to traffic.
In production, a model is only one part of the release. Outcomes depend on preprocessing code, feature version, inference configuration, post-processing rules, and rollout mode. That is why “validation metric improved” is not enough to claim readiness for live traffic.
This article gives a practical framework that can run in CI/CD without manual interpretation. It uses verifiable criteria and leaves minimal gray zones at release time.
What should count as a release unit
A stable ML release is an artifact bundle, not one model.bin:
- model version and signature;
- feature pipeline code and input schema;
- post-processing rules and business thresholds;
- serving infrastructure profile;
- release gates and thresholds.
If any of these elements changes, it is a new release and the full validation cycle must run again.
Where production ML actually breaks
Most incidents are not caused by a “bad” neural network. They are caused by environment mismatch:
- training-serving skew: production input differs from training context;
- wrong optimization target: offline score rises while business impact drops;
- stable latency in test, unstable latency under peak traffic;
- cost increase after rollout due to changed input distribution;
- rollback exists formally, but does not restore the full previous working state.
These risks are solved by release discipline, not by swapping the model.
Reference framework: 7 release gates
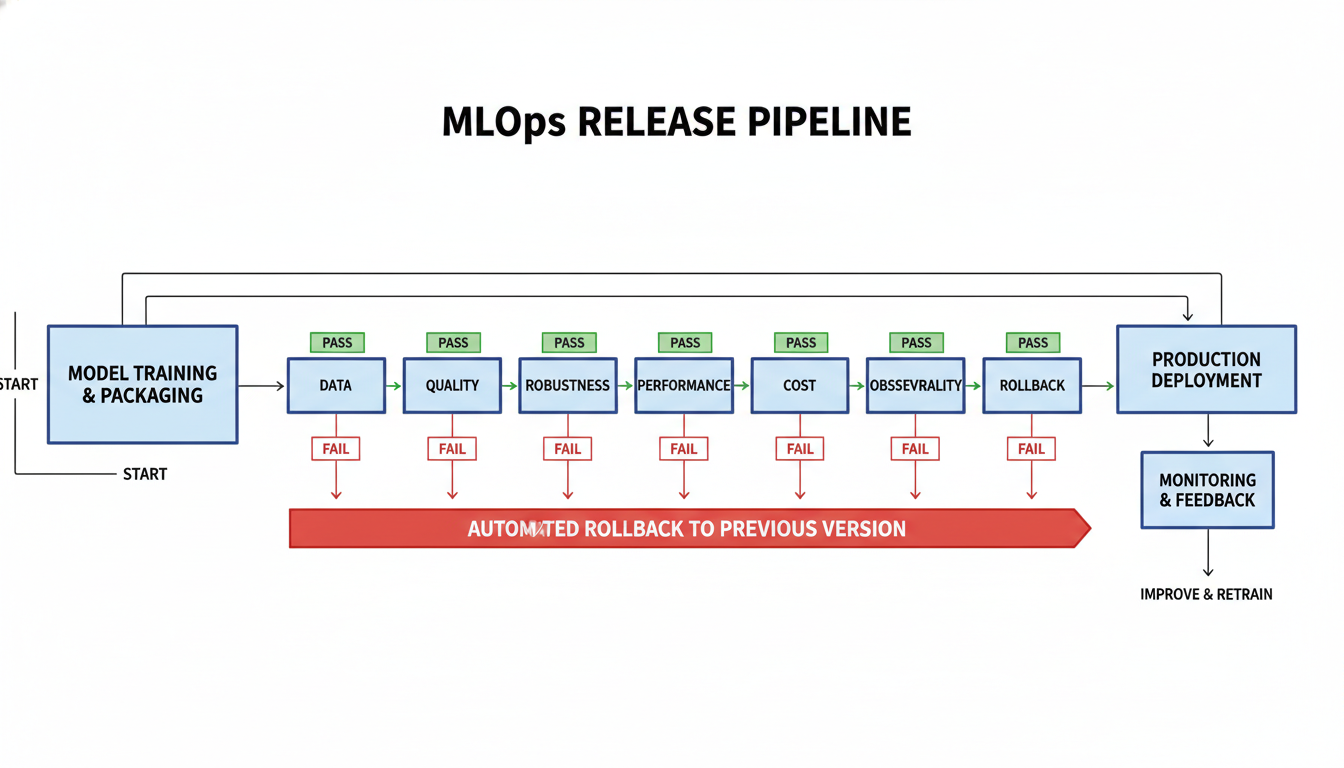
Seven release gates that must pass before controlled rollout.
| Gate | What is validated | What blocks release |
|---|---|---|
| 1. Data gate | schema, freshness, validity, input shift | inconsistent or stale input data |
| 2. Quality gate | task metrics and slices vs baseline | quality or calibration regression |
| 3. Robustness gate | edge scenarios, resilience, policy checks | fragile behavior on boundary cases |
| 4. Performance gate | p95/p99 latency, throughput, timeout share | SLO breach under target load |
| 5. Cost gate | cost per useful outcome | non-viable economics at target quality |
| 6. Observability gate | traces, metrics, alerts, ownership | blind operations after rollout |
| 7. Rollback gate | atomic rollback and tested runbook | high risk of prolonged outage |
Each gate is binary: pass or fail. “Almost passes” is not a production state.
Gate 1: data
Data gate checks that model input is reproducible and operationally valid.
Minimum set:
- schema compatibility for required fields and types;
- freshness against SLA for all critical sources;
- basic quality checks: null/range/enum/outlier;
- shift checks on critical features vs reference distribution.
For drift control, statistical tests by column type are usually enough. Evidently provides standard drift components for tabular and text fields: docs.evidentlyai.com/metrics/explainer_drift.
Gate 2: quality
Quality gate protects against fake improvement in the aggregate average. Validate at least three layers:
- primary task metric;
- critical business slices;
- calibration or ranking stability.
Practical baseline:
- classification:
PR-AUC/F1plus calibration (BrierorECE); - regression:
MAE/RMSEplus error by key target ranges; - ranking/recsys:
NDCG@K/Recall@Kplus cold-slice behavior.
If a model wins overall but fails a critical slice, release is blocked.
What counts as proven improvement
To prevent random fluctuations from passing the gate, define a statistical contract:
- minimum sample size for comparison;
- acceptable degradation boundary
deltafor non-inferiority; - decision by confidence interval, not by a single point estimate.
Working rule:
pass if lower_95(metric_new - metric_base) > -deltaIf this condition fails, release is blocked even when metrics look visually close.
Gate 3: robustness
This gate separates an “accurate” model from a “survivable” system.
Minimum scope:
- edge-case sets: missing values, rare categories, extreme ranges;
- behavior under degraded dependencies;
- fallback paths for timeout or empty feature responses;
- policy checks for sensitive actions and data.
For LLM/RAG systems, add injection resistance and unsafe tool-call controls. Principle stays the same: validate safe behavior, not text quality alone.
Gate 4: performance
Performance is evaluated on target traffic shape, not local benchmark shape.
Minimum set:
p95/p99 latency;- throughput under peak load;
- timeout and error shares;
- cold-start path and warm path separately.
SLO is fixed before release, not adjusted after failed test runs. For SLO alerting, burn-rate patterns from SRE Workbook are practical: sre.google/workbook/alerting-on-slos.
Gate 5: cost
“Cost per request” often hides real economics. The control metric should be cost per useful outcome.
cost_per_useful_result =
(inference_cost + infra_cost + storage_cost + retraining_cost + human_ops_cost) / success_countUse at least two thresholds:
- hard cap for cost per useful outcome;
- guardrail for increase vs current production baseline.
Release must fail if quality improves but economics degrades beyond threshold.
How to calculate cost without self-deception
A formula without accounting rules creates false precision. Define this before release:
- horizon:
7dfor operational control and30dfor financial decision; - fixed-cost allocation by service traffic share;
- one-time migration cost tracked separately from steady-state.
Minimum practical pair:
cost_per_useful_result_7d
cost_per_useful_result_30dRelease passes only if both stay within threshold and do not degrade baseline economics.
Gate 6: observability
If root cause cannot be localized quickly, observability is effectively absent.
Minimum coverage should include four planes:
- infrastructure: CPU/GPU, memory, saturation, network errors;
- model: prediction distributions, drift, quality proxies;
- product: successful scenario share, escalations, cancellations;
- economics: cost by model, service, traffic segment.
Hard requirement: one trace_id across gateway, feature lookup, inference, and post-processing.
Practical SLO alert profile
For services with SLO 99.9%, a multiwindow burn-rate setup works well. In operations, this reduces noise while still catching long degradations.
Practical starting profile:
- page: burn-rate 14.4, windows 1h and 5m;
- page: burn-rate 6, windows 6h and 30m;
- ticket: burn-rate 1, windows 3d and 6h.
These values are a good starting point for 99.9% SLO with a standard error-budget model. For low-traffic or batch systems, thresholds should be recalculated to avoid false alerts.
Gate 7: rollback
Rollback is ready only if the operation is atomic for the whole release:
- model;
- preprocessing code;
- threshold configuration;
- dependent runtime parameters.
Readiness criteria:
- rollback can be launched as one operation;
- latest stable versions of all artifacts are available;
- rollback RTO is measured in drills, not estimated;
- incident runbook has an owner and was tested in simulation.
Without this, rollback does not actually reduce outage risk.
Anti-patterns that must block release
The following signals should stop rollout immediately:
- “model was retrained, feature code version was not fixed”;
- “offline eval passed, canary was skipped”;
- “alerts exist, but ownership and runbook are not assigned”;
- “cost per useful outcome was not measured, only request price was tracked”;
- “rollback plan exists, but has never been tested in a drill”.
If any of these is true, it is pre-release technical debt, not post-release cleanup.
Release contract: what to store in CI/CD
Minimal release card that makes rollout verifiable and reproducible:
release_id: ml-2025-12-26.3
artifacts:
model_uri: models:/churn-model@candidate
feature_pipeline: feature-pipeline:v18
preprocessing_image: registry/preproc:1.12.4
postprocessing_config: thresholds:v9
gates:
data_gate: pass
quality_gate: pass
robustness_gate: pass
performance_gate: pass
cost_gate: pass
observability_gate: pass
rollback_gate: pass
rollout:
strategy: canary
steps: [5, 25, 50, 100]
auto_rollback_on:
- p99_latency_ms > 800
- error_rate > 0.8%
- cost_per_useful_result > 0.42This structure is simple, but it sharply reduces the chance of undocumented “spoken” releases.
Fast release check: 12 questions before rollout
If any answer is “no”, release should not go out:
- A reproducible release artifact package exists.
- Data gate passed on current input slice.
- Quality gate passed on baseline and critical segments.
- Robustness gate passed on edge-case sets.
- Performance gate passed under target traffic profile.
- Cost gate fits useful-outcome budget.
- Observability covers request-to-response execution path.
- SLO alerts are configured and owner-bound.
- Canary plan and auto-rollback criteria are fixed.
- Rollback was tested and RTO measured.
- Incident runbook is updated for this release.
- A 24-hour post-release verification is assigned.
Tooling that covers the baseline stack
A practical open stack is usually enough:
MLflowfor experiment tracking and model registry. For new stacks, prefer aliases and artifact versioning over legacy stage flow: mlflow.org/docs/latest.Prometheus + Grafanafor system and SLO metrics.Evidentlyfor data/prediction drift and delayed quality checks.- team CI/CD orchestrator for automated gate validation and rollout.
For an applied LLM context, the same principle is detailed in MLOps for a Support RAG Agent in 2026.
30-day implementation plan
Week 1: release policy formalization
- lock SLO/SLA and business useful-outcome metric;
- define release unit and mandatory artifacts;
- add data gate and quality gate to CI.
Week 2: operational resilience
- add robustness gate and performance gate;
- run load profile close to production;
- lock release-blocking criteria.
Week 3: observability and economics
- enable drift and quality-proxy monitoring;
- configure SLO burn-rate alerting;
- add cost gate and weekly review of
cost_per_useful_result.
Week 4: safe rollout and rollback
- run canary with auto-rollback;
- run incident drill and measure real rollback RTO;
- close postmortem with gate updates.
After this, release is no longer a manual risk event. It becomes an engineering process with measurable control.
Where not to overengineer
For a small internal service, four gates are enough at start: data, quality, performance, rollback. Cost and observability gates can be added in stages, but only with fixed ownership and deadlines. Otherwise, temporary simplification turns into permanent risk.
Summary
Production MLOps is a system of decisions before and after model rollout. A strong model without release discipline still produces an unstable service. A 7-gate control loop gives predictable rollouts: clear criteria, reproducibility, fast rollback, and transparent useful-outcome economics.
FAQ
What is a release gate in production ML?
A release gate is a mandatory pass-fail check for one risk domain, such as data integrity, quality, latency, cost, observability, or rollback readiness.
Can one strong metric replace release gates?
No. A single offline metric cannot cover runtime reliability, traffic behavior, or economics. Gates protect against cross-domain regressions.
How many gates should a team start with?
Start with a minimal but strict set across data, quality, performance, and rollback, then add cost and security controls as traffic and risk increase.